
The goal of this project was to create a bot that can solve Wordle using machine learning techniques and then make the bot play the Rootstrap version of the game. Wordle is a game where players have six attempts to guess a five-letter word that changes every day. The machine learning solution used for this project is reinforcement learning, a technique that learns by interacting with the environment. The final solution involves using the A3C algorithm and a game state representation based on Andrew Ho's solution. The model achieved 99% effectiveness for a 1000-word case and 95% effectiveness for the full-size problem.
What is Wordle?
Wordle is a game from the New York Times (Wordle - A daily word game) where players have to guess a five-letter word in six tries. Every day, a new puzzle is released with a different word to guess. In the Rootstrap version, the length of the word changes between four to six letters in each puzzle.
The rules are simple:
- Players have at most six attempts to guess the word.
- Every day, the word to guess is the same for everyone.
- Each guess must be a valid English word.
- The color of the letters changes to indicate if the letter is in the word and in the correct position.
- Green: the letter is in the word and in the correct position.
- Yellow: the letter is in the word but in the wrong position.
- Gray: the letter is not in the word in any position.
It's important to note that the word can have repeated letters, meaning the same letter can appear in different positions, and each occurrence is painted in the corresponding color.
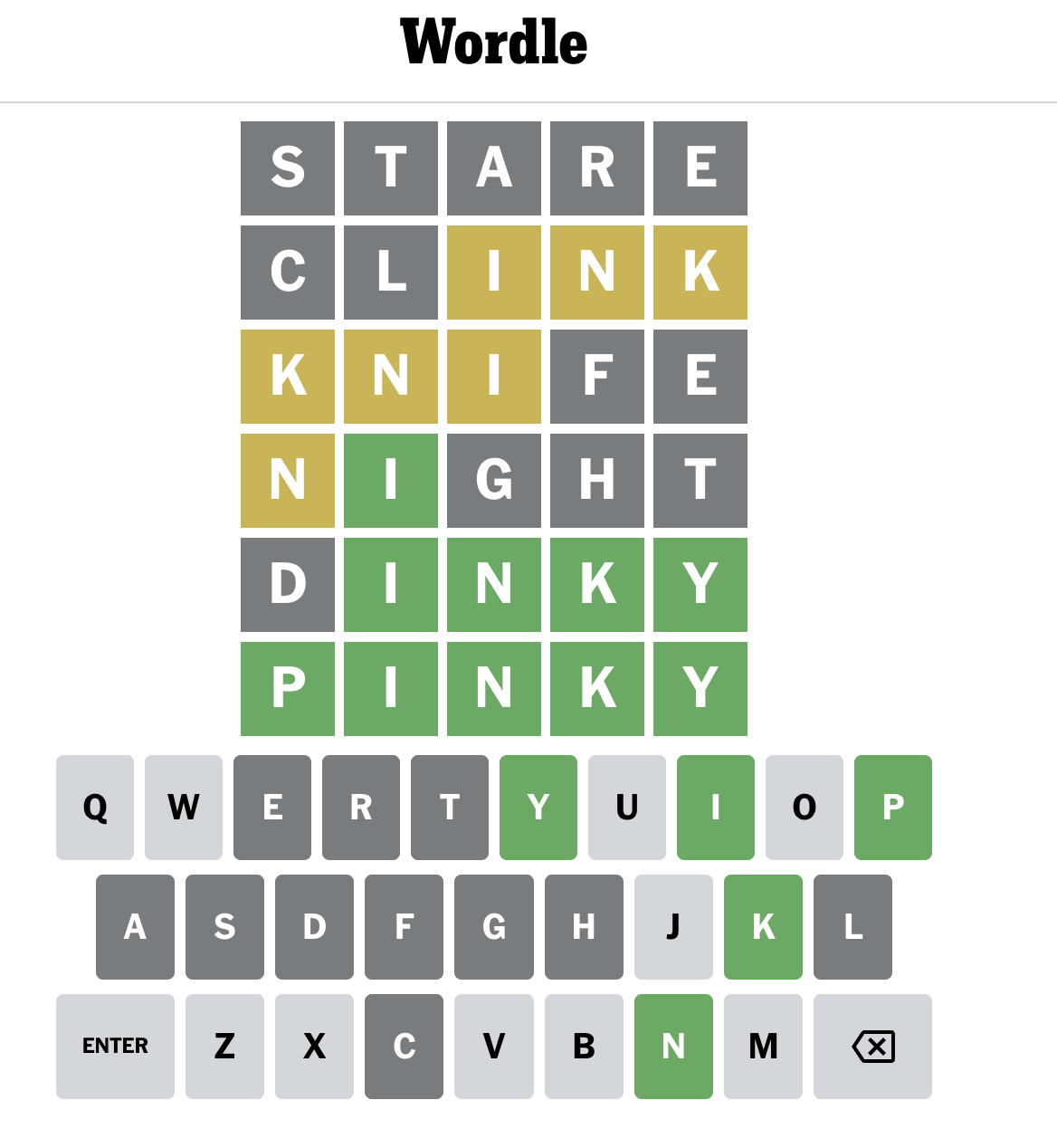
Figure 1. Screenshot of a won Wordle game.
Brief Introduction to Reinforcement Learning
Reinforcement Learning is a type of machine learning technique where an agent learns by interacting with an environment. The agent takes actions in the environment and receives rewards as feedback. Based on the rewards obtained (positive or negative), the agent learns to take the right actions through trial and error. An example of reinforcement learning is training an AI agent to play a video game. The agent receives rewards for achieving game objectives, such as reaching a certain level or collecting items. It learns the optimal sequence of actions by exploring the game environment and receiving feedback from the actions performed, without human intervention or prior knowledge of the rules or strategies. There are several algorithms for reinforcement learning, such as Deep Q Learning, Actor Critic Agent (A2C), and Asynchronous Actor-Critic Agent (A3C). If you want to learn more about RL and its algorithms, the following videos and blogs are recommended: The foundations of Deep RL YouTube video series, and blogs Deep Q Network with Pytorch and Asynchronous Actor Critic explained.
Solution and Ideas Along the Way
Reinforcement learning algorithms consist of two main components: an agent and an environment. The environment represents the problem to solve, which in this case is the Wordle game. It has a state (the Wordle board), a set of possible actions (all 5-letter words in the English alphabet), and knows how to update its state based on an action and the rewards obtained (green, yellow, or gray outcomes). On the other hand, the agent is the entity that decides which action to take in each state (policy) to maximize the reward. This decision is often made by a neural network.
To implement the solution, several decisions needed to be made:
- How to represent the game state and actions.
- The specific policy the agent will follow, including the number of layers and nodes in the neural network.
- The reinforcement learning algorithm to use (DQL, A2C, A3C, etc).
After researching, Andrew Ho's solution was found, which used reinforcement learning with the A2C algorithm and achieved 99% effectiveness. This solution served as a starting point for building the environment and the neural network based on his implementation. In his solution, the game state is represented as a one-hot encoding of each letter's information in each position of the word for the game day (whether the letter goes in that position or not). For more information about his solution, refer to Andrew Ho’s blog.
Andrew Ho's solution and the A3C algorithm were combined to build the final solution. A3C is the latest state-of-the-art algorithm, providing advantages such as faster convergence, better parallelization, and the use of CPU cores instead of GPUs. Three different state representations were tested:
- Binary simpler state.
- Cosine state.
- Improved Andrew Ho's one-hot encoding state.
The binary simpler state represented the letters used in the last attempt with binary encoding, along with an integer encoding of the outcome. However, this solution failed as the model was unable to learn. The problem was that it only used information from the last attempt and ignored previous attempts, resulting in the loss of valuable information.
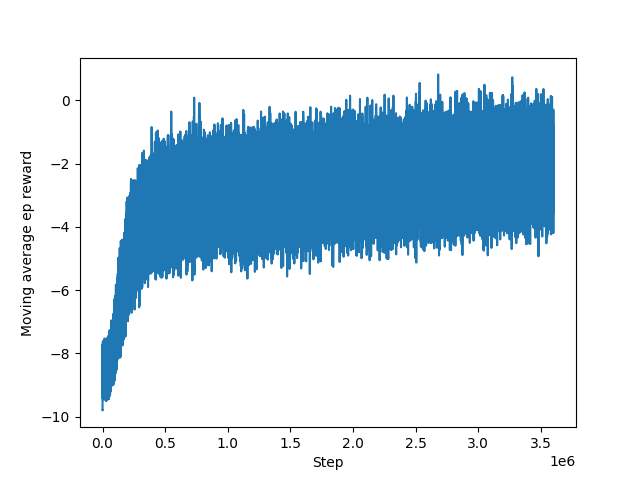
Figure 2. Training with a binary state solution with 50 goal words.
The cosine state represented the letters using cosine and sine functions applied to their integer representations, while also keeping track of all the attempts and outcomes. This approach resulted in a slow learning curve, requiring millions of games to train the model even for a problem with a vocabulary of 100 words. The resulting model's win rate was also not optimal.
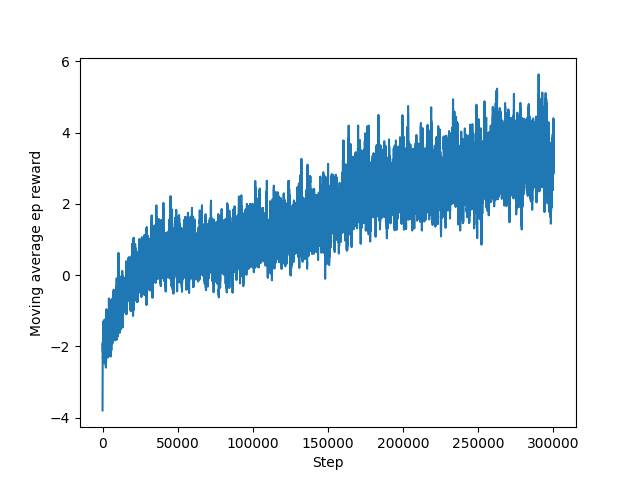
Figure 3. Training with a cosine state solution with 50 goal words
The most successful solution was a modification of Andrew Ho's approach, which involved using a one-hot encoding of each letter's state in every position to represent the game. For example, the representation of the letter "A" when a green output is obtained in the first position (indicating that an "A" must go in the first position) is:
[[0, 0, 1], [0, 1, 0], [0, 1, 0], [0, 1, 0], [0, 1, 0]]
This representation was improved to address cases where the state update process previously ignored attempts with repeated letters. Additionally, a reward for correctly guessing a letter was added to the existing reward for winning the game.
After resolving initial bugs, the model started learning. Initially, it achieved an 86% win rate on the full-size problem. However, after making changes to the model and hyperparameters, better results were obtained. Changes included adjusting the number of layers, the activation function of the neural network, and the modification of the gamma hyperparameter, which regulates the importance of the reward during network updates. The network used has one hidden layer with a tanh activation function in the middle and a softmax function as the output to choose among all the possible actions.
To test different approaches, the problem was divided into different sizes: a 100-word game, a 1000-word game, and the full-size game. This approach, taken from Andrew Ho's solution, helps test the model on a smaller, more solvable problem initially and then scale the solution to the real problem. The resulting model trained for the 1000-word problem served as a baseline for training the full-size problem.
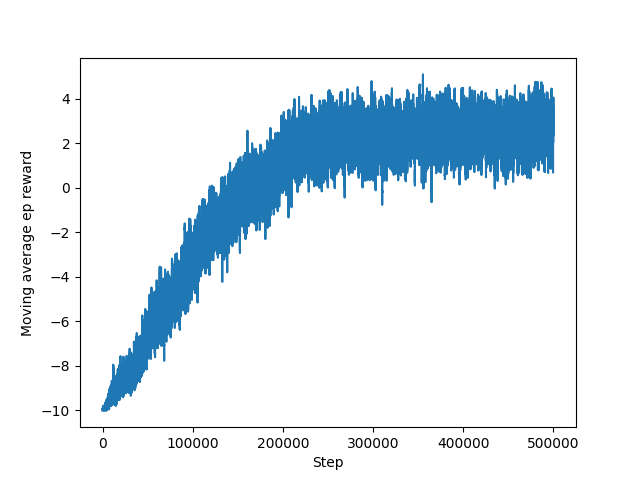
Figure 4. First training with one-hot encoding state and default hyperparameters, with 100 goal words.
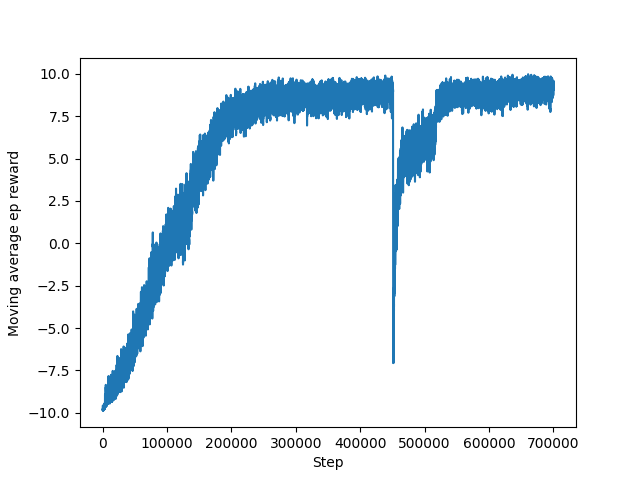
Figure 5. Training with one-hot encoding state and hyperparameters gamma and seed improved, with 100 goal words.
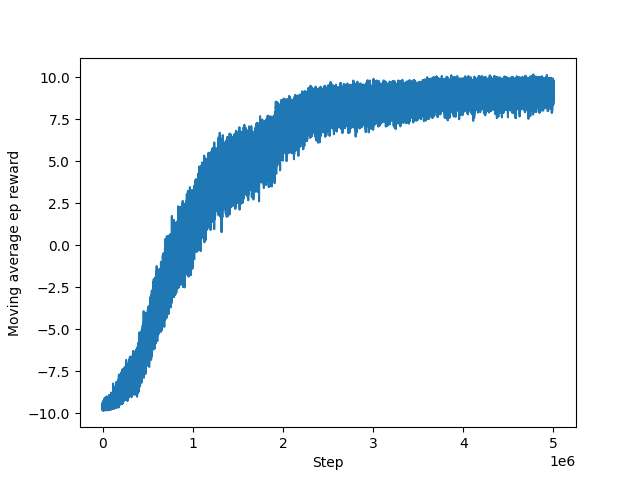
Figure 6. Training with one-hot encoding state and hyperparameter gamma and seed improved, with 1000 goal words.
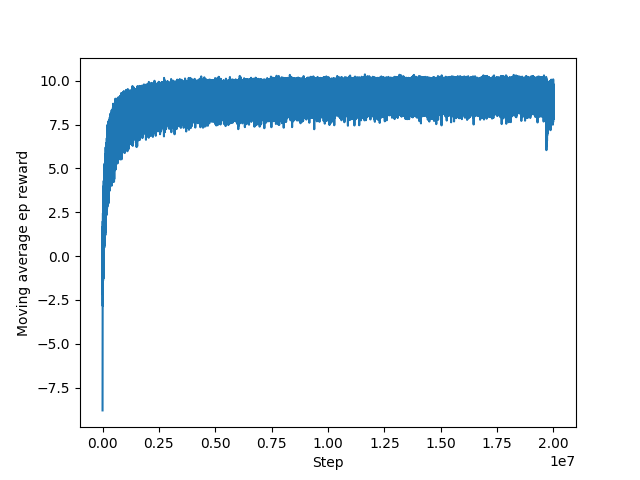
Figure 7. Training with one-hot encoding state and gamma and seed improve, full size problem trained from 1000-word trained model.
Results and Conclusion
The model achieved 99% effectiveness for the 1000-word case and 95% for the full-size problem. It took approximately 1-3 million games to reach this level of performance for the 1000-word game, and an additional 2-3 million games for the real-world problem with around 2300 words.
Training the full-size problem model from the pretrained model of the smaller problem was very successful. This approach reduced the number of iterations as the pretrained model didn't have to learn all the new words from scratch and started making educated guesses based on the knowledge it already had.
Although the one-hot encoding representation of the state provided better results, other representations such as using cosine functions are worth considering and exploring further. Alternative methods of representing letters and game outcomes could potentially reduce dimensionality, enabling faster model training.
While there are other solutions that don't use reinforcement learning, such as using information theory or classic ML algorithms like minmax, the goal of this project was to utilize reinforcement learning techniques.
Once the model was able to solve most of the 5-letter words in the game, it was possible to make it play the Rootstrap version of Wordle. A demo video of the final model playing the Rootstrap version of Wordle can be accessed at https://youtu.be/3X6O6xEfnxQ. The demo was done using Selenium, a software tool that allows programmatic control of a web browser, simulating user interaction.
Additionally, the Wordle version of Rootstrap has been adapted to allow users to interact with the AI and make it guess a word through a user-friendly UI, which can be accessed at https://ai-player--rs-wordle.netlify.app/.


