





Counter caches are great until you get 20,000 people following the same influencer and the counter cache on that person locks the whole database.
The goal of this post is to go through the basics of counter caches explaining possible alternatives to overcome this.
What are counter caches for?
Counter caches were created to cache the counts of associated records.
Imagine we are developing a social media application where we have influencers and fans:
CODE: https://gist.github.com/brunomichetti/80ae491541279a0ecff19106def5103d.js
Everytime we display an influencer in the list we want to show how many followers he has.
The naive approach to achieve this is doing a count of the associated fan records for each influencer.
CODE: https://gist.github.com/brunomichetti/b2c19e2d28860f2898267dfe92363685.js
While this might be enough if we are rendering only one influencer, it definitely does not scale well if we are going to render a list of many influencers, since it's going to trigger a select count query for each influencer.
CODE: https://gist.github.com/brunomichetti/5c482433762be498bf0f4ebc56e36a14.js
In the logs we get:
CODE: https://gist.github.com/brunomichetti/f1019d330e725c08bf441f4b01566c72.js
… and goes on for each influencer...
That's when counter caches gain importance. Counter caches are a built in Rails feature that allows you to track the associated records count by doing almost nothing. It only requires you to add a new integer column in the influencers table and let the associated model know that it has to update that column every time a records gets created or destroyed (or is no longer referencing the influencer).
To use Rails counter caches you need to create a migration to add a new integer column to the associated model:
CODE: https://gist.github.com/brunomichetti/32c741a863e942a9d9a1be4b990ffe57.js
Let the FanInfluencer model know it has to update the counter cache in the influencer model:
CODE: https://gist.github.com/brunomichetti/45bc3194e66b24cdf8b08a769307a792.js
Reset the counters for existing records with:
CODE: https://gist.github.com/brunomichetti/f54e7a7949b56064db61af1e361eaba1.js
And then you are ready to use the new column like you would with any other attribute:
CODE: https://gist.github.com/brunomichetti/c45f3e2238fd3e0e45a4b1302853c15e.js
Using the new counter cache the db will execute only one query that will select the influencers to be rendered, since fans_count is now just a column on the influencer and no counts or joins with other tables are needed.
CODE: https://gist.github.com/brunomichetti/16598bd7d4474221922e8291758f28ff.js
(Should you need more complex counter caches, consider using Counter culture gem that works around some deficiencies in Rails original counter caches.)
So... what's the problem?
Counter Caches have a fairly simple implementation using callbacks to keep this column updated. Every time a fan influencer record is created, updated, or destroyed, the counter cache on the corresponding influencer needs to get updated. This might make these type of operations slower. If that's a cost you can take, go ahead. But consider the following situation:
Imagine a very famous influencer has been advertised and suddenly all of our users click on 'Follow'. Every 'Follow' action on that influencer creates a fanInfluencer record, which will end in the db trying to execute many update queries to the counter cache of the influencer around the same time, locking up that db row and making our users requests time out. Ugh...
First solution.
Use an SQL alternative to dynamically calculate the count without falling into the n+1 problem raised before introducing the counter caches.
We need to add the following scope on the influencer model:
CODE: https://gist.github.com/brunomichetti/ebb43620e746b31622958c985c6d3121.js
When we load the influencers to render we need to use the new scope:
CODE: https://gist.github.com/brunomichetti/3c5a6396945c92442c86bb0107f81fd0.js
And then we just call [.c-inline-code]fans_count[.c-inline-code] for a particular influencer to get the counter.
In the logs we get:
CODE: https://gist.github.com/brunomichetti/dfb476810f5bf8796887e7ea3508a480.js
This solution is slower than having the counter cache when rendering the influencer list since the latter one only has to select attributes of the same table. However, using this method you don't need to keep any counter cache column updated, making create/destroy/update actions on the [.c-inline-code]fan_influencer[.c-inline-code] table simpler since they don't trigger any callback afterwards. The db lock problem will go away.
So, this SQL alternative could be appropriate for you if:
- You have many create/destroy/update actions on the [.c-inline-code]fan_influencer[.c-inline-code] table in comparison to requesting the influencers fans count.
- Your app is prone to facing situations like the mentioned above, where the counter cache of a single record could get updated more times in a small period of time than it can handle.
Comparing the three approaches
We measured the time it took to request all the influencers each with his fans count using the three different approaches. In the db there were only 10 influencers and 1,000 fans, all the fans following all the influencers. The times are calculated as the average Active Record time of 5 runs.
Method #1: Using naive approach (fans.count)
18.6ms
Method #2: Using counter cache column
0.5ms
Method #3: Using SQL dynamic count
3.7ms
Second solution.
Store the changes of the counter in a buffer in a faster storage first (like redis or Memcached) to later update the real value in the database.
After a [.c-inline-code]fan_influencer[.c-inline-code] record has been created or destroyed, the value in the redis cache for the influencer key is increased or decreased by one. After a couple of seconds, the count value for the redis key is added (or subtracted) to the counter cache in the db, and reset to 0.
A good idea is to also use a recalculation job once in a while, to make sure the counters are updated with the real count value, compensating for transient errors that may cause the deferred counters to drift from the actual value.
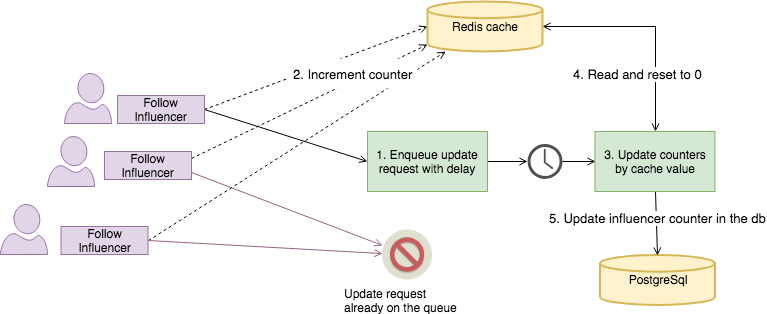
There are many gems that help you achieve this if you don't want to implement it yourself.
In this post it was used Wanelo gem to enqueue the jobs for me, but since it hasn't been committed to since Oct 7, 2016 you might want to implement that part yourself.
Next it's explained how to achieve this using that gem and assuming you have redis and a background worker installed. In this case it was used Delayed Jobs as the worker but you will see that it is very simple to modify the solution to use another one.
Start by configuring the gem with:
CODE: https://gist.github.com/brunomichetti/418b65760974596505cbcc1c94575841.js
Let the fanInfluencer model know how to use the counter cache:
CODE: https://gist.github.com/brunomichetti/ecb78d63898df01b0738e67d84a0a542.js
Create a method in the influencer to update the count to the real value
CODE: https://gist.github.com/brunomichetti/d09afa0869e6ae3e25575e6edd270aae.js
And here is where the fun part begins.
The gem adds a callback after a FanInfluencer record gets created or destroyed that triggers the enqueue method in the class called [.c-inline-code]CCWorker[.c-inline-code] as we configured before. So we need to create this class:
CODE: https://gist.github.com/brunomichetti/8a8e71237c526d457e90e927646ec7b9.js
As you might have noticed, the enqueue method decides which Enqueuer class to delegate the execution to depending on the option [.c-inline-code]cache[.c-inline-code]. Since the gem is the one that makes the calls to this method with the right arguments, we just need to implement those two modes knowing that we will receive two calls after a fanInfluencer has been created or destroyed: one for recalculation and one for deffered.
We can begin by creating the parent Enqueuer class, that decides if the job needs to be enqueued or if it's already pending.
CODE: https://gist.github.com/brunomichetti/41f074d8a82fc52aa9e4034ed7cf1943.js
We will now implement the deferred mode, for which we will define the [.c-inline-code]execute[.c-inline-code] method that will be called by the asyncrhonous worker once the time is up. For this mode the gem comes with a counter class that does the buffering and updating part for us, so we just need to use it.
CODE: https://gist.github.com/brunomichetti/800bdc372a7539809ab59ac97777e30e.js
For the recalculation mode, we will call the method that we defined in the influencer at the begging, to reset the counter agains the real count. The name of this method comes in the options so we need to invoke it.
CODE: https://gist.github.com/brunomichetti/ea6c41e5473d9e808e5c7f7bf59a4d41.js
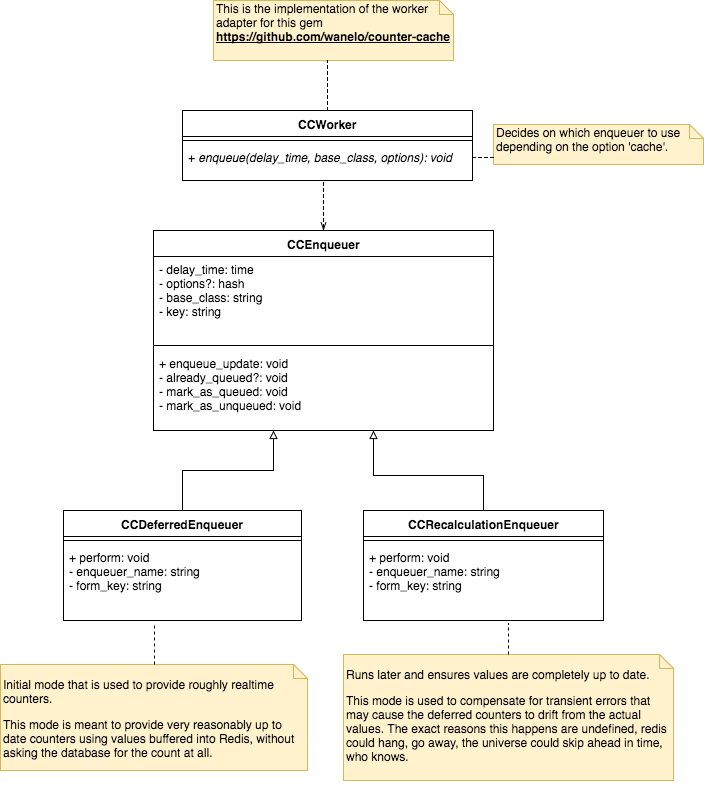
And that's it.
Now we can try creating and destroying fans and influencers and we will see how their count changes after the number of seconds that we picked, and a recalculation job is enqueued for later.
To test it, we can create 100 fans that would follow Taylor Swift.
CODE: https://gist.github.com/brunomichetti/2f12f602b23ed84a9fd9f785384a14ba.js
For each fanInfluencer created we can see logs like the following, where after the [.c-inline-code]fanInfluencer[.c-inline-code] record is created, two delayed jobs are inserted:
CODE: https://gist.github.com/brunomichetti/c79529efe855584ca62831abdbb0dcb3.js
You can see in the redis cli console how the new keys are created, with the values 100 in the key for the buffer managed by the gem, and a 1 in the other two keys that mark the corresponding jobs as enqueued so they won't be enqueued again. In this case [.c-inline-code]104[.c-inline-code] that you see in the key name corresponds to the id of the influencer created.
CODE: https://gist.github.com/brunomichetti/df075670c92a2b9927d200a1c2ed9d0f.js
After the 20 seconds (or whatever you configured for the env var) have passed, if you turned on your worker, we can see Taylor Swifts fans count has been raised.
CODE: https://gist.github.com/brunomichetti/667e70c2fc9f2fe40e7237f713c59f9e.js
To test the recalculation mode, we can update the fans count to any other incorrect value and wait until the recalculation method fixes it.
Notice that when using Delayed Jobs, since two jobs need to be enqueued (inserted into the db) after a fanInfluencer has been created, the [.c-inline-code]follow[.c-inline-code] action is in total slower than before when no other [.c-inline-code]follow[.c-inline-code] action is being performed at the same time. However, under big load the row contention problem does not happen, making this approach more efficient in that case.
Since the solution for the enqueuer does not depend on the influencer model, you can reuse it for any other counter cache that you may want to optimize, just by configuring the counter cache in the associated class and defining the recalculation method.


