
Crowd counting refers to the technique used to estimate the number of people in an image or video. It finds applications in various industries, hospitals, crowd gatherings, as well as automated public monitoring like surveillance and traffic control. Unlike object detection, crowd counting focuses on identifying arbitrarily sized targets in different scenarios, including sparse and cluttered scenes simultaneously.
Crowd counting tasks can be broadly categorized into two types:
- Dense crowds: Occurs when a large number of people are densely packed in a specific area.
- Sparse crowds: Refers to situations where people are scattered with significant gaps between them.
Sparse crowd counting is relatively easier compared to counting dense crowds, which requires more sophisticated algorithms.
Techniques
Several techniques have been developed to address the challenges of crowd counting. Initially, computer scientists employed basic machine learning and computer vision algorithms such as detection, regression, and density-based approaches to predict crowd density and density maps. However, these methods faced challenges such as scale and perspective variations, occlusions, non-uniform density, and more. Subsequently, researchers turned their attention to Convolutional Neural Networks (CNNs) due to their effectiveness in various computer vision tasks, aiming to leverage their capabilities in developing crowd counting algorithms.
Counting by Detection
This approach focuses on counting by detecting individual objects, specifically people. There are three types of crowd counting by detection, based on the features used to identify crowds in images and videos:
- Integral-based Detection: This method uses the full-body appearance of people, extracting features like edges, shapelets, textures, Haar wavelets, histogram of oriented gradient (HOG), etc. Then, it uses learning approaches such as SVMs, boosting, random forests, clustering or other algorithms are employed to detect or classify objects and ergo count people. However, this approach is limited in its effectiveness for sparse crowds.
- Part-based Detection: Instead of considering the entire human body, this technique focuses on specific parts, such as the head or shoulders, and applies classifiers to those parts. Estimating the presence of a person solely based on the head is not reliable, so combining the head and shoulders provides better results, particularly for dense crowds.
- Shape Matching: This method uses ellipses to draw boundaries around humans and then employs a stochastic process to estimate the number and configuration of shapes.

However, counting by detection is not highly accurate when dealing with dense crowds and significant background clutter. This is where counting by regression comes into play.
Counting by Regression
Counting by regression does not involve segmentation or tracking of individuals, but focuses on learning a mapping between image features to the number of individuals, which result in better performance, specially with dense crowds. Depending on the regression goals, this crowd counting method can be divided into two groups:
- Individual based regression: As stated before, this technique extracts low-level features such as edge details and foreground pixels, and applies regression modeling to map these features to the count. For example, in this paper, researchers first normalized the foreground of the image and then used the extracted local foreground, edge and texture features to learn multiple regression to get the number of individuals in the image. However, this method lacks robustness in the scenarios with large changes in light, perspective, crowd distribution, crowd density, etc.
- Density based regression: This approach focuses on estimating density by learning the mapping between local features and object density maps, effectively incorporating spatial information. So, it avoids the dependence on the detector by learning the mapping of images to density maps. Instead of learning each individual separately, this technique tracks groups of individuals simultaneously. The mapping can be linear or nonlinear. For instance, a random forest regressor is used in this paper to vote for densities of multiple target objects, thereby learning a nonlinear mapping. A "crowdedness prior" parameter is defined to handle the differences between crowded and uncrowded image patches, resulting in two different forests corresponding to the prior.
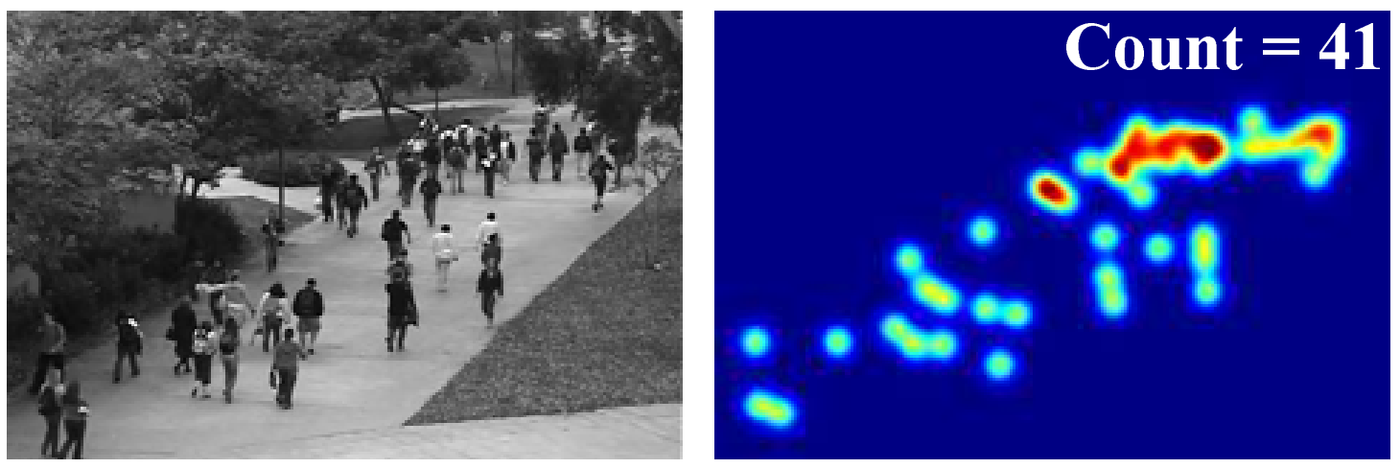
Although these techniques get better performance in both sparse and dense scenarios and alleviate the dependency on the detector, they still rely heavily on handcrafted features. As a result, the feature extraction algorithm became an essential limitation for regression-based methods.
Counting using CNN
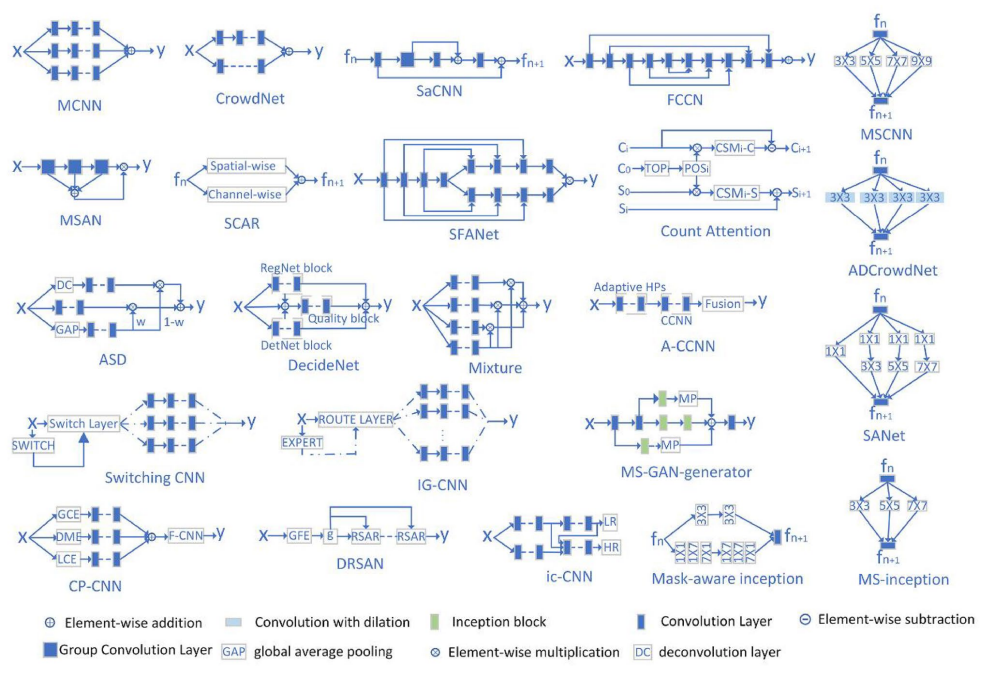
In the more recent years, given the powerful feature extraction capabilities of CNNs in deep learning, researchers tried to use them to automatically extract features and trained an end-to-end network to count individuals. The methods can adapt to changes in various factors, predict the number of individuals more accurately and achieve the state of the art on many popular evaluation benchmarks. CNN-based methods outperform other approaches in scenarios involving a wide range of human head scales, non-uniform density distributions, and significant variations in perspective and scene. This dominance of CNN-based approaches is evident in the current landscape of crowd counting research. Li et al. (2021) divided the CNN crowd counting methods in 7 categories:
Although this technique gets better performance in both sparse and dense scenarios and alleviates the dependency on the detector, it still relies heavily on handcrafted features. As a result, the feature extraction algorithm became an essential limitation for regression-based methods.
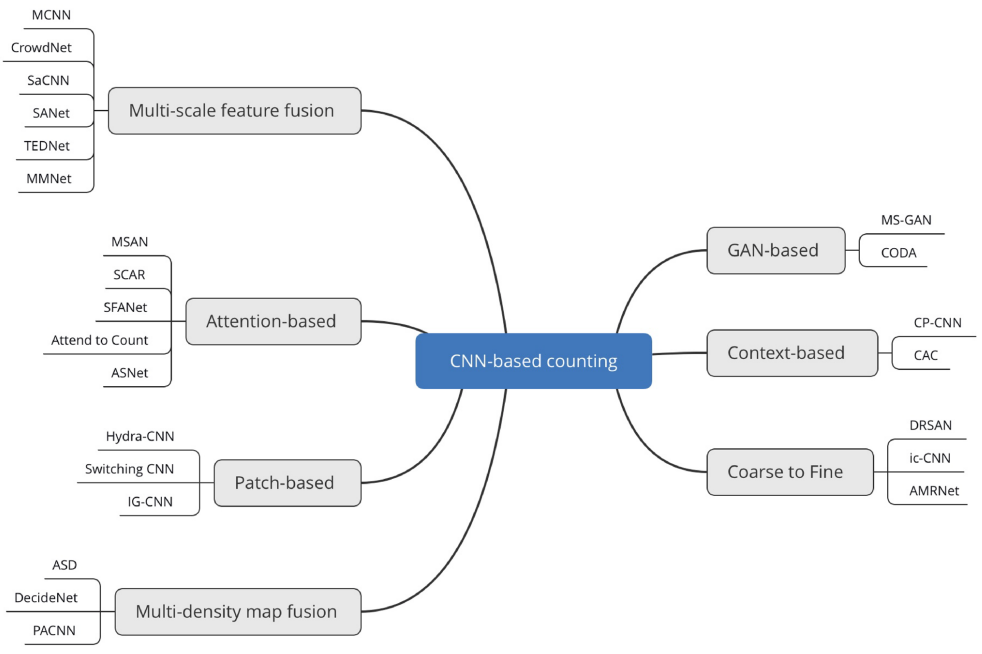
- Multi-scale fusion: Methods such as MCNN, CrowdNet, and SaCNN focus on fusing features of different scales to handle varying head scales and crowd sizes. They use multi-column convolutional networks or scale-adaptive convolutional neural networks for feature extraction and fusion.
- Attention-based: Approaches like MSAN, SCAR, and SFANet utilize attention mechanisms to address challenges such as changes in head scales and complex crowd scenes. Attention is used to guide the network to focus on important regions and improve counting accuracy.
- Patch-based: Hydra-CNN, Switching CNN, and IG-CNN divide images into patches and count them separately, addressing uneven crowd density. They employ various techniques such as adaptive patch response, selective network branching, and incremental learning.
- Multi-density map fusion: Methods like ASD and DecideNet fuse density maps of multiple scales or levels to handle varying conditions. They use weight information or adaptive calibration to combine density maps and improve counting accuracy.
- GAN-based: GAN-based approaches, such as MS-GAN, leverage adversarial networks to generate more accurate density maps. Generative and discriminative models compete to understand the distribution of crowd data, leading to improved counting performance.
- Context-based: CP-CNN and other context-based methods utilize contextual and semantic information to constrain density maps. They integrate global and local context information to generate high-quality density maps.
- Coarse-to-fine: Coarse-to-fine approaches, including DRSAN and ic-CNN, initially generate a coarse density map and then refine it for finer counting results. They use recurrent spatial-aware networks or multi-stage fusion to enhance the density map quality.
Video-based Crowd Counting
The methods mentioned above are used for still images. Nevertheless, recently, researches have started working on crowd counting in video format, considering that video sequence contains timing information that is beneficial to counting. Some of the main examples are:
- ConvLSTM: ConvLSTM models utilizes the temporal correlation between video frames to improve crowd counting accuracy. They replace fully connected layers with convolutional layers to capture spatiotemporal information effectively, allowing for a better understanding of the relationship between space and time. +info
- LSTN: LSTN incorporates a Locality-constrained Spatial Transformer module to explicitly capture spatiotemporal dependencies in videos. It consists of a density map regression module and an LST module that associates density maps of adjacent frames to produce more accurate density maps. +info
- E3D: E3D exploits the power of 3D convolution to encode spatiotemporal features in videos. It uses modulation weights and short skip connections to highlight useful features and simplify model training. The architecture called temporal channel-aware (TCA) is used to capture time dependence and fuse local and global spatiotemporal information. +info
- Cross-Line Pedestrian Counting: This method focuses on counting pedestrians crossing virtual lines in dynamic and dense crowds. It includes local crowd density estimation and cross-line pedestrian counting. It enhances spatial consistency and employs a two-stage solution to address uneven density, involving density level division and expert regressors for each level. +info
- Dynamic region division: To ensure counting accuracy and preserve the integrity of counting objects, a dynamic region partitioning algorithm is proposed. It segments the distal and proximal regions based on object bounding boxes and scene segmentation lines. Different detection methods, including YOLOV3, are employed for near-end and far-end areas, and the results are fused to obtain global distribution information. +info
Other Deep Learning methods
In the fascinating realm of crowd counting and density estimation, researchers are constantly pushing the boundaries to develop innovative methods beyond the conventional approaches. While we have already explored the seven main categories and video-based counting, numerous other remarkable works deserve recognition. Let's delve into some of these groundbreaking contributions that have reshaped the field and elevated the accuracy and efficiency of crowd counting:
- RDNet: Lian et al. (2018) proposed an RGBD-based network architecture called RDNet, which locates a person's head during crowd counting. It uses a regression model and a detection model, with a depth adaptive kernel and depth-aware anchor to enhance robustness and detection performance for small targets. +info
- LSC-CNN: Sam et al. (2020) developed LSC-CNN, a detection model that utilizes density maps to improve face detection for small targets. +info
- CSRNet: CSRNet is a popular crowd counting method known for its good performance, simple architecture, easy training, and generalization capabilities. It combines VGG16 for feature extraction and dilated convolutional layers for network expansion. +info
- Background Noise Reduction: To address high background noise, researchers have used branch-based methods to separate the background and foreground of an image, enhancing the accuracy of density maps. +info +info
- Perspective Correction: Techniques like utilizing camera angle, height, and vertical field of view (Kang et al., 2016) or feeding multiple scales of the input image (Marsden et al., 2017) have been employed to address perspective changes in crowd counting. +info +info
- Privacy Protection and Other Applications: Efforts have been made to count individuals while protecting privacy (Chan et al., 2008), detect pedestrians in still images (Oncel, 2008), enhance density map estimation through foreground/background segmentation and local uncertainty estimation (Arteta et al., 2016), and apply deep residual structures for crowd counting, violent behavior detection, and density classification (Marsden et al., 2017). +info +info +info +info
- Network Design: Some studies have used Neural Architecture Search (NAS) to design the network structure (Hu et al., 2020), proposed lightweight models for structured knowledge transfer (Yang et al., 2020), and employed reinforcement learning to transform the counting problem into sequential decision-making (Liu et al., 2020). +info +info +info
- Weakly Supervised Learning: Yang et al. (2020) introduced a weakly supervised network that counts based on the number of individuals in an image, without requiring location supervision. +info
These works explore different aspects of crowd counting and density estimation, employing techniques such as neural architecture search, knowledge transfer, sequential decision-making, semi-supervised learning, weakly supervised learning, and feature extraction using unlabeled data. They contribute to improving accuracy, efficiency, robustness, and generalization in crowd counting applications.
Conclusion: Pros and Cons of Crowd Counting Techniques and Optimal Usage
Crowd counting is a crucial technology with applications in diverse fields, ranging from crowd management to surveillance. Over the years, various techniques have been developed to address the challenges associated with accurately estimating crowd sizes in different scenarios. In this survey, we explored three main categories of crowd counting methods: counting by detection, counting by regression, and counting using Convolutional Neural Networks (CNNs). Additionally, we examined video-based crowd counting and other innovative deep learning methods that have revolutionized the field. Let's now summarize the pros and cons of each technique and the optimal scenarios for their usage.
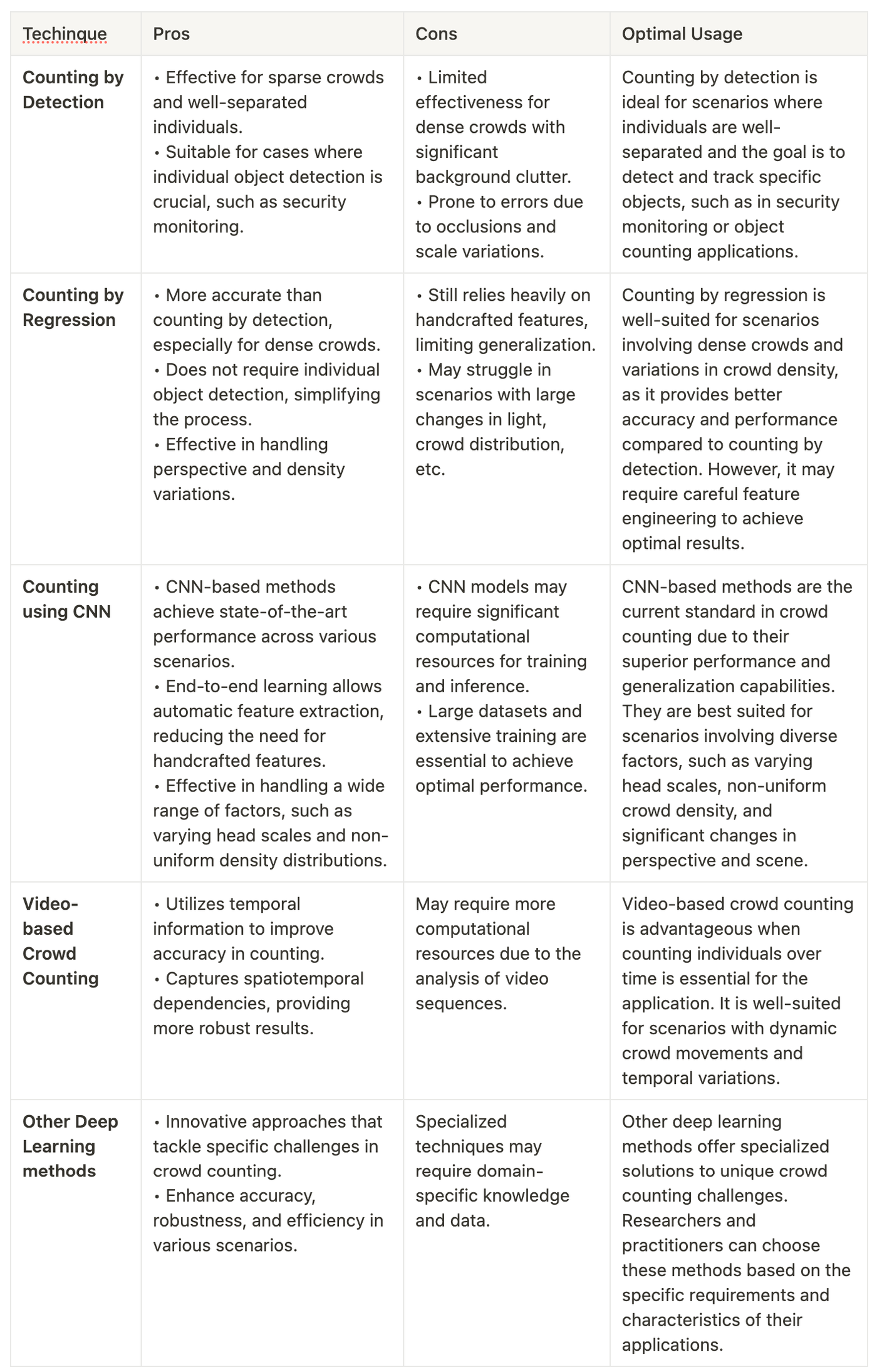
In conclusion, crowd counting is a dynamic and rapidly evolving field with a wide range of techniques and methods. Each approach has its advantages and limitations, making it crucial to select the most suitable technique based on the specific requirements and characteristics of the crowd counting application. Whether it's counting by detection, counting by regression, CNN-based methods, video-based counting, or other innovative approaches, careful consideration of the strengths and weaknesses of each method will lead to accurate and efficient crowd counting solutions for various real-world applications.


