
This past year, the Rootstrap Devops Team faced the challenge of building a social network from the ground up. In this article, I will explain how we built the infrastructure using AWS in a reliable, performant, and affordable way.
The Beginning
When the project came to us, we were tasked with building a POC for a social network that would include live video streaming, written articles, articles in the form of video, and all the features that a social network normally has for users to interact with each other, among other things.
We had to determine the most suitable architecture and services and make many decisions without knowing the technologies that would go into making the application. With that in mind, we couldn't go without some basics.
IaC
We wanted to have the infrastructure we could spin up in the least amount of time possible, whether it was to build a new environment or to recreate one if needed, and we wanted to do it in the best possible way. That's where Terraform came in.
Using AWS, we could've gone with Cloudformation; being native, one would think it has the upper hand there, but Terraform simplifies and does so many things, so much better than us; it was a no-brainer.
With Terraform, you can break down your infrastructure into modules, allowing you to build your services independently, test them independently, and reutilize them as much as you want.
You also have third-party modules available, which can speed up your development. In our case, we used some third-party modules initially to have the environment quickly available for developers and then switched to self-written modules.
Docker
The second thing that was a no-brainer was to use Docker containers for our front and back end. It allowed us to build an application that we could scale in or out as needed, use any technology the development team felt was appropriate later on, and allow for portability when devs had to test things locally.
Also, it provided a benefit from a security standpoint, as we would always build containers from the latest version of their OS. We kept them on Amazon ECR, which scans for vulnerabilities and allows us to build alert triggers if any vulnerabilities are discovered.
Moreover, we went with ECS with Fargate to orchestrate our containers for added benefits. We did not need the kind of granular control EC2 would provide, with this being a POC for a starting company.
The main objective was to do demos for potential investors and be a starting point for their social network; we could pay for the resources we used instead of having to pay for compute resources that would be idle a lot of the time(especially on lower environments) and simplify later to the customer the management of their application.
At this stage, Fargate proves itself the best option, reserving for later the possibility of switching to ECS/EC2 or EKS if the customer's needs change over time.
Leveraging AWS Services for Optimal Solutions
The later steps involved a few weeks for discovery, where Devs and DevOps had a better chance to determine the best technologies for the project. Here we finally discovered that the frontend would run Next with SSR, and the backend with NestJS, which was perfect for our container solution.
We also decided to use a relational database instead of a non-relational one, using Amazon Cognito for authentication, and for the live streaming, we would go with Amazon IVS.
Regarding the database, we suggested using AuroraPostgres instead of RDS Postgres as it offers advantages on scaling, performance, replication, consistency on replications, and more.
Authentication with Cognito also offered advantages as we were going to set up the whole infrastructure on AWS; we could use it for user authentication, social media sign-in, and API authentication.
And finally, we went with IVS. We never implemented live streaming with the POC, but IVS was a clear winner over any alternative. It solved everything for us, scalability, availability, and performance. It's cheap, simple to set up, and proven in massive use (Twitch uses it, among others).
Navigating the alternatives was a bit discouraging as other options required a much more expensive process in terms of development and infrastructure. Here, leveraging the AWS networking infrastructure, we wouldn't add unnecessary latency to the streams.
Application Pipelines
For our application pipelines, we went with AWS CodePipeline; again, there are multiple ways of going about it, some way more complex, but we felt CodePipeline makes for a good one in our POC context.
It's native to AWS, simple to set up, and allows for interesting things like running the DB Migrations to update our database. In contrast, the application version backend is being updated directly from within our own network as another step of the backend pipeline.
GitOps Pipeline
To allow multiple people to work together on our IaC, we developed a GitOps pipeline on GitHub Actions. GHA allowed us to create PRs when developing our IaC, get any errors in our Terraform Plan added as comments to the PR, and then decide whether we wanted to continue by applying the changes (merging the PR) or not (closing the PR).
This goes well with doing code reviews of the infrastructure code and also permitted extra security as AWS Admin Keys didn't need to be locally stored but lived as GitHub repository secrets.
Other Considerations
This is a multi-account setup, where we keep a main account as admin; we use it for the backend of our Terraform states, to manage the root DNS domain, and other administrative tasks on AWS, such as SSO. We also keep one account per environment so that each is independent.
Overview
We use GitHub Actions for our GitOps Pipeline, allowing us to code review our infrastructure changes and merge them only after they are reviewed and the plan is executed successfully.
The application pipelines for the front and backend live on AWS Codepipeline. We have multiple accounts, one per environment and an additional administrative account for SSO, DNS management, TF State, and other tasks.
Our database runs on a multi-az AuroraPostgres Cluster, which has a lot of benefits in terms of replication, performance, and scalability.
The front and backend with Docker containers run on ECS/Fargate, Amazon Cognito for API and User Authentication, and Application Load Balancers for handling front and back end traffic to save costs on API Gateway, at least for the POC.
WAF is protecting the Cognito and Load Balancer endpoints, and AWS CloudFront was used in front of the front end and an S3 bucket for image and video assets. And finally, a bastion host for access to DB when needed.
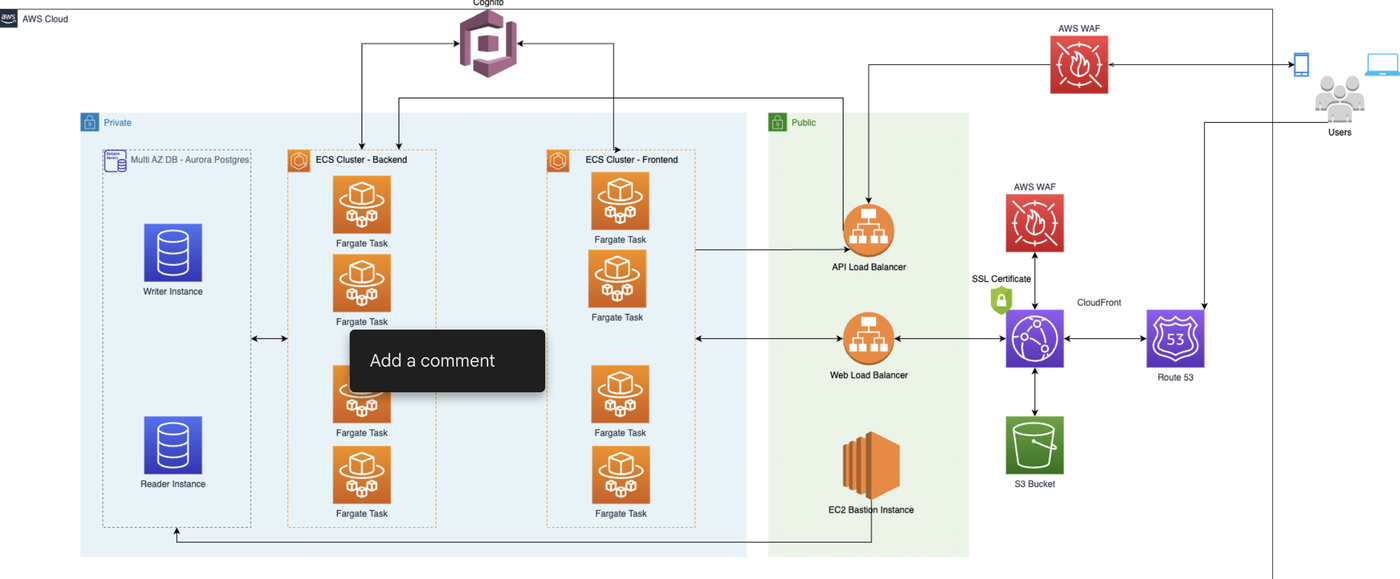
AWS Cloud
This approach is a simple, cost-effective, performant solution that can be adapted easily in case there's a need for Production use.
How We Built It
Now that we covered our solution and you have a good understanding of what we built, we will explore some of the details.
IaC with Terraform
We designed our Terraform structure following the best practices, creating modules to reutilize code, encapsulating configuration for different AWS Services on specific modules, and keeping configuration organized.
Still, in the image below, you can find a sample of our structure, and If you pay attention, you may notice we didn't modularize IAM.
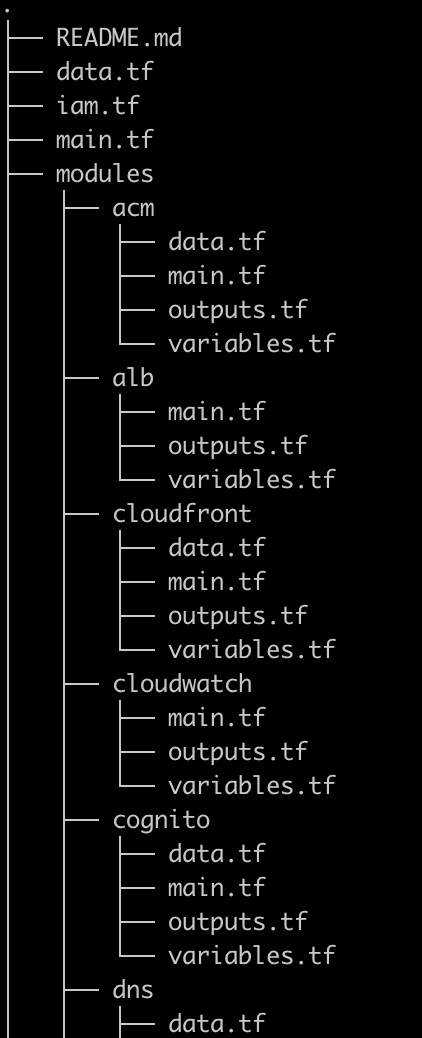
IaC Terraform Structure
We started with a flatter structure, still separating code into different files for organization, but we migrated pretty early on to the modular structure. Still, it's sometimes difficult to move existing resources into a new structure, as Terraform maps the resources to your code in the state file.
To do this without destroying your resources, you'd need to import them from CLI into your module manually. In this case, IAM is in some technical debt, as there were other priorities, and such a simple group of resources didn't justify the effort.
Based on this experience, we'd recommend starting from the beginning using a modular structure; even if your modules start very simple, you can give them more complexity over time, adding more features without having to destroy the resources to create new ones from a module, or import them manually (which is not the simplest and can be messy).
In either case, you'd never manually edit a state file for such a situation; please be mindful that if you corrupt the file, you will break the link between your code and the created resources.
Going back to the good practices, after we started moving to modules and developing directly into them, we found it to be a much better process. Even for readability and understanding how the code itself works, it makes it much better.
You can go to the base main file and see what each module is called and with which parameters. If you go into each module, you can find the code specific to each and find exactly what is being created and how.
This results in a much cleaner main module that you can easily review. We will use our pipeline module as an example:
CODE: https://gist.github.com/DiegoGarciaRS/d00fe78b53446e8eba4b1affb0cff376.js
This is what it's called from the main module, and you have a module type of resource that has a source. In this case, it's a local folder in our repo containing the module code, but it may be something else, like a link to a GitHub repo where a module is hosted, for instance.
We are currently developing a module library common for the DevOps team that will be hosted in the Rootstrap GitHub repository. When we create a new base project, all the modules will be referenced from there.
After that, you have a list of parameters required for the modules defined in the variable.tf files within the module's structure that are required to create all the necessary resources.
In the case of a library like the one we are building, it's important to build good documentation on these parameters instructing possible values, format, and other important information so that whoever is consuming the modules has a clear understanding of how to use them.
Here is a look at some of the code in our module:
CODE: https://gist.github.com/DiegoGarciaRS/873cdb4bccfd27f7a26c65798dcd69cf.js
We start by making a call to another module, the S3 one. Notice that if we weren't using modules, we would need to rewrite all the code we have on the S3 module here again, which would make it unnecessarily complicated to maintain and update.
Then we have some code to create an ECR Repo that will be used in the pipeline and a lambda function to grab the results of the vulnerabilities scan on ECR and push them to a CloudWatch log group. We have alerts then built on top of that to send a notification to a Slack channel if any vulnerabilities are found.
It might've been another good choice to keep these non-pipeline resources that we consume in a separate module or modules, especially if you were building something reusable among many projects.
But, in the context of our POC, we found this to be a good solution that is clear and also has the benefit that if you create a new pipeline, you don't need to concern yourself building each of the different parts independently.
You can populate the required parameters, and the module itself will take care of everything; ultimately, how you design your modules will depend on how tightly coupled you want them to be and your use case. Here's how:
CODE: https://gist.github.com/DiegoGarciaRS/4f40ab8f8c8b9bf07b99477ff87af73e.js
AWS CodePipeline
The final part of the Pipeline module is the pipeline itself, built on AWS CodePipeline and composed of a couple of different resources. As seen in the code below, it's composed of the pipeline itself, with the source stage and the deploy stage built on it, and then, as a separate resource, we created the Build stage.
CODE: https://gist.github.com/DiegoGarciaRS/d89b8061b6f92a15a37bb99a1030e9e3.js
In the case of the backend, we have an additional "Migration" step, which is a build that executes some steps against our database; we built it using CodeBuild because that allows us to create a machine within our VPC that has connectivity to our DB and install the prerequisites for DB access there, and finally, just execute the steps.
GitOps Pipeline
We decided to create one from scratch on GitHub Actions, as given the scope of the project, it made sense not to add new tools specifically for this, and with the costs of it being already included in the GitHub Product our customer was paying, it didn't add any extra expense(please view here billing for GHA if you intend to use them).
Adding a GitOps pipeline brings a lot of benefits, such as:
- It promotes teamwork, allowing for better visualization and tracking of historical changes in the infrastructure code.
- More security as no one needs to have locally stored admin credentials to execute the Terraform; those live as a secret within GitHub.
- Automation of the deployment steps, no need to manually "terraform init," "terraform plan," "terraform apply," etc. All those are done automatically as part of the pipeline.
- Collaboration, as it helps with code review; when you make changes and want to apply them, you submit a PR that can be peer-reviewed. When the PR is first created, it executes a terraform plan that you and reviewers can look into, as the output for that plan is pasted as a comment on your PR so that you can decide whether to approve, merge (and to apply) or not.
This is a simple diagram of how the flow worked for us, we had DevOps as our lowest environment, so when new changes were to be done, we branched from there, made the changes, and then created a PR from New Branch to the DevOps branch.
From there, we would create other PRs in the rest of the environments following the sequence from lower to highest.
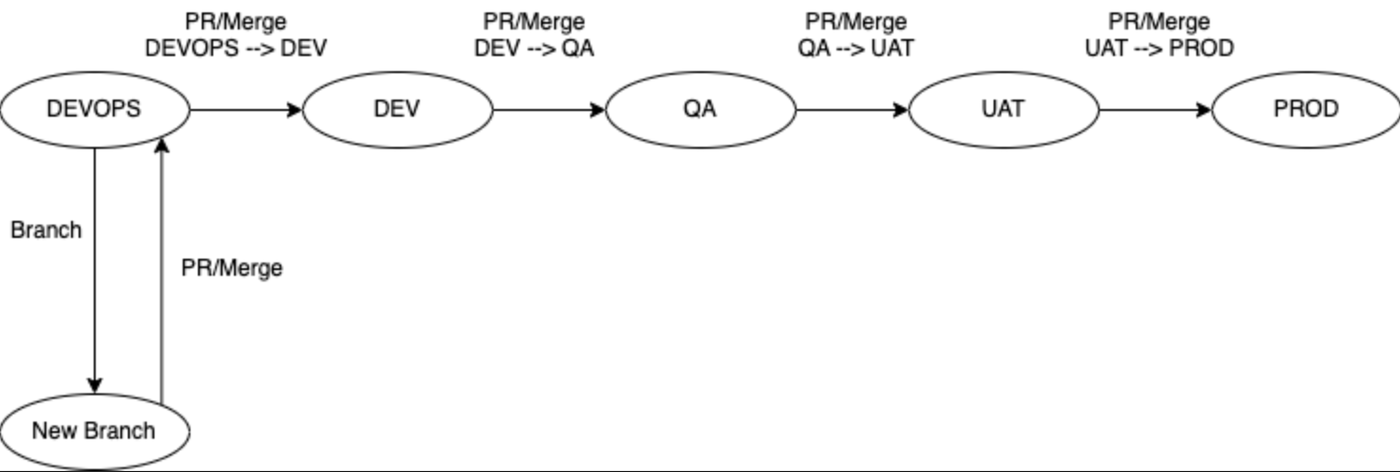
GitOps pipeline flow
Our Pipeline is divided into two parts, a "caller" workflow that is what is triggered when the PR is created/merged. Here is a look at the first part:
CODE: https://gist.github.com/DiegoGarciaRS/347dbf1b5cb99bac2333e90da4b4b603.js
And a second part with the pipeline jobs themselves that are "called" by the main "caller" workflow. The second part is as follows:
CODE: https://gist.github.com/DiegoGarciaRS/d4b682178729f987eba0be00e6e2f474.js
These configurations live within the repo, in a .github/workflows folder, and are automatically picked by GitHub and created as actions.
Amazon Cognito
Another service I'd like to highlight is Amazon Cognito, which helped us solve authentication for our users by providing a secure service, fully integrated with AWS, that handles user creation by allowing Social Login with Google quite simply.
After creating users, we also have a user object on our database to track individual posts, comments, videos, etc., linked to the Cognito Identity. By providing an authentication layer, it interacts with Google as IdP and then with our backend to complete the login process into our application.
Another use we gave to Cognito was for internal Administrator users, which we used along with AdminJS for the moderation within our app. Cognito allowed us to centralize the management of these administrator accounts, integrate admin user creation with our Terraform so it could be done automatically when AdminJS is deployed, and do it in a way that is both secure and almost effortless. Take a look:
CODE: https://gist.github.com/DiegoGarciaRS/0489815619396385b060d0e8efb8cd1d.js
The Future
As we continue adding complexity, growing the team, and maturing the solution, there are new roads for improving the above-proposed infrastructure and its management.
We look into tools like Terragrunt to further improve our terraform code, Kubernetes for containerization for increasing production loads that require a more robust solution, multi-region setup for the application leveraging a global aurora database, and more.
What to take away
This article shows how at Rootstrap, we use the latest technologies to make the best possible solutions for our customers.
We don't just pick them because they are trendy; we choose them based on how they will impact the solution (development speed, quality of the product, reliability, availability, and more), on the customer needs (both in terms of maintainability and costs) and the best practices for security and compliance.
What are your thoughts on our approach? How do you think we did with this build? Let us know in the comments.


