
In data science, the theory in practice is not always the same as reality. When working with data, it's not uncommon to be presented with several complex problems. Fortunately, you are not alone and there are blogs, slack channels, and useful information to come to the rescue.
Plenty of problems are often presented during the stages of data cleaning, model design, and model execution. These problems are generated by the complexity and scope of the data in question. Problems can also occur from the size or characteristics of data and the number of its features, as well as the hyperparameters in play, and any introduced errors during the data cleaning process.
The aim of this article is to highlight potent problems related to data science, and provide insight on the following questions to help you overcome such setbacks:
- Which presented data should I use?
- What is the right amount of data to use?
- How can I effectively process incoming data in real-time?
- How should I deal with complex datasets, unlabeled data, & datasets w/ missing values?.
These are just some of the problems that you may be presented with when handling data. It's important to tackle these issues correctly as this crucial data will act as the base for your algorithm.
Let's take a look at some of the possible solutions for these common problems.
Not Enough Data Presented
Data is an important contributor for training algorithms and if enough is not presented, it can often lead to inaccurate predictions. Some methods for generating data can be used in order to get a bigger dataset to train your model.
First off, if you know the possible values you are looking for, then you might be able to randomly generate those values. Additionally, you can use input analysis to understand the distribution of data and from there simulate values based on its distribution.
When working with images, you can use data augmentation to increase the size of your dataset. Keep in mind, it's important to understand the meaning of the data in question to help generate valid inputs.
Also, when working with small datasets, it can be easy to overfit the data. So, to avoid this problem, you can apply techniques such as feature selection, regularization, averaging, or cross-validation. Another issue with small datasets is that outliers and noise in the data can become problematic, so in those cases, you cannot skip the study of outliers in your data.
Too Much Data Presented
Data scientists need to be careful here, as having more data does not guarantee that your model will be accurate. You might use fewer data and find that your model not only performs better but is also faster. It really comes down to choosing the appropriate data and training the model correctly.
In fact, large sample sizes can cause the p-value to be deceptively small, which shows that the perception of all variables is dependent on each other. If you have too much data, you can take a sample or several samples from the data to train your model in use.
Training with the whole dataset when you have too much data is near impossible, as you would need a lot of computational power and memory to process the data. It would simply take too much time. A better practice is to take a stratified sample that is representative of the data.
This way you are sure that the data is representative, as it contains the same proportion for classes as the full dataset. If there is still too much data, you can always process it in chunks, parallelize the computation in a cluster, use a database to save the data, or use one of the trending big data technologies at your disposal.
How Much Data Should I Use?
There is no set rule when determining the sample size of data as it depends on the data type, and the context/complexity of the problem in question. It's best to do your research on similar problems to estimate how much data you would need.
Here are some ideas to help you take an effective sample of data:
- Take a sample that contains a certain percentage of each class to ensure all cases are covered. Or, take a stratified sample, which contains the same proportion for the classes in play.
- Follow these rules of thumb based on heuristics:
- For the number of predictor variables: Take 70 or 60 times the number of variables. For example, if you have 10 variables take a sample of 700 rows.
- For multiple regression analysis: The desired level should be between 15 to 20 observations for each predictor variable.
- For factor analysis: Take at least 10 observations per variable. It's recommended to have more than 300 rows.
If you are interested in reading more on this, you can do so here:
- https://stats.idre.ucla.edu/spss/output/factor-analysis/
- https://scholarworks.umass.edu/cgi/viewcontent.cgi?article=1144&context=pare
- https://stats.stackexchange.com/questions/45820/minimum-sample-size-for-pca-or-fa-when-the-main-goal-is-to-estimate-only-few-com
- https://easyai.tech/en/blog/how-do-you-know-you-have-enough-training-data/
Too Many Variables
If your data has too many predictors it can be difficult to understand and can make the computational time longer. Also, there might be predictors that are highly correlated with one another. This phenomenon is known as multicollinearity, which can lead to skewed or misleading results when analyzing the effect of predictor variables in a statistical model.
Also, when there are high-dimensional spaces in the data, this can lead to the unwanted curse of dimensionality coming into play. This happens when the dimension increases and the volume of the space grows in such a manner that the available data becomes sparse, and objects appear to be dissimilar in more ways than one.
Because of this, sparsity can be problematic for methods that are based on statistics, as the amount of data needed to find reliable results grows exponentially as the dimension increases.
Therefore, if some of these problems are presented, you will need to apply dimension reduction techniques to reduce the number of columns in your dataset to allow you to understand the model more clearly.
Feature Selections
When determining what type of correlation best to use, the type of variables in the dataset will help to determine the best type of correlation to put in place. Here is an example highlighting such possible cases.
ContinuousCategoricalContinuousPearson’s CorrelationLDACategoricalAnovaChi-Square
- Pearson Correlation: A number between -1 and 1 that indicates the level at which the variables are linearly related.
- Anova: Provides a statistical test that compares the difference between means
- Linear Discrimination Analysis (LDA): Finds a linear combination of variables that separates into groups as a categorical variable.
More information on feature selections can be found here:
- https://www.analyticsvidhya.com/blog/2016/12/introduction-to-feature-selection-methods-with-an-example-or-how-to-select-the-right-variables/
- https://machinelearningmastery.com/feature-selection-with-real-and-categorical-data/
- https://datascience.stackexchange.com/questions/893/how-to-get-correlation-between-two-categorical-variable-and-a-categorical-variab
- https://michaelminn.net/tutorials/r-categorical/
Categorical Data
It's not uncommon to find that working with categorical data can often leave you with a headache. Here are some of the problems that you may encounter:
- Data Lacking Labels: The data that you need to categorize does not have obvious labels, and you might need to perform some transformations to get certain labels. Doing this step correctly is crucial for an effective algorithm learning procedure.
- Imbalanced Data: A dataset might contain a small number of cases for a certain class. For example, if you are classifying whether it is an error or not, you might have little information for error cases. So, to ensure that you are getting those cases when doing the sample, you might need to perform oversampling.
- Too Many Categories: If a variable has too many categories, or if there is no order over the categories, eventually the variable will need to be transformed to dummy variables. This can affect the model performance and make the data difficult to understand. You can prevent this by grouping the categories or applying dimension reduction before performing your model.
Streaming - Real-Time Processing
Depending on the circumstances, input data can come in a flow or at an ongoing set time. If the amount of information being ingested is huge, you will need to automate the process and use certain tools that facilitate this type of processing.
There are several tools that through configuration will let you set the flow of actions to process data, schedule inputs, and generate outputs in several formats.
These tools are extensible, so you can customize their functions to create something specific. This can be used to predict new input data that is incoming or to improve the model's functionality by re-training it to perform better.
Big Data
Big Data technologies are used to process large amounts of information in real-time. It's not uncommon for people to confuse machine learning with big data. However, both terms are not the same and can be applied together or independently.
Machine learning with a lot of information might need the use of Big Data, and Big Data does not necessarily mean applying machine learning models over the data, as it might only be used to make certain queries or set up alerts.
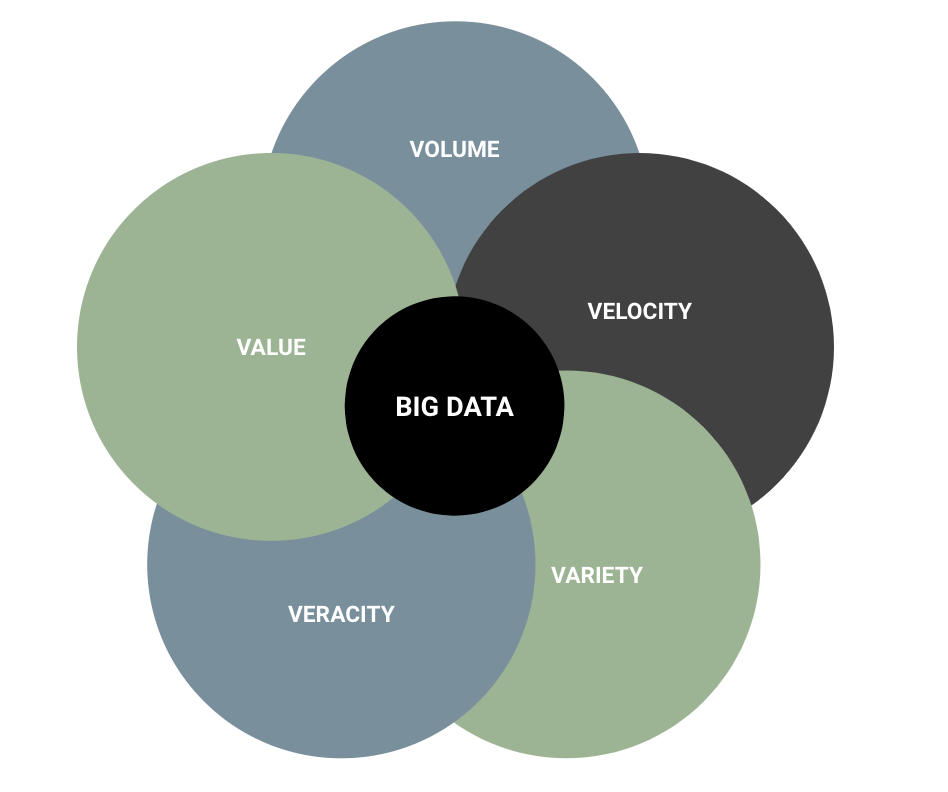
Big Data is a combination of the 5 following characteristics, called the “5Vs” of Big Data:
- Volume: A large amount of information
- Variety: Data comes from different sources
- Velocity: Data needs to be processed quickly
- Veracity: Thedegree to which data can be trusted
- Value: Datasets that may need to be combined & processed to generate value
When managing big data, the consistency of the data becomes less important than previously mentioned. Instead, it turns out that the availability and speed of processing that is reached by partitioning are more important.
As the CAP Theorem states, we cannot have these three conditions at the same time. This implies a huge change in the culture of the organization. Migrating to Big Data implies not only a paradigm change but also a technology change since other tools and infrastructure are needed
Data management and governance are needed to handle a wide variety of information from different sources and formats. This helps in avoiding corrupted data and establishing standards for processing while saving and protecting the data. In turn, making the data available trustable and usable.
Platform
Generally, a common platform will be used to perform all the big data activities such as input data, processing, and storing. This platform is in a cluster mode. Hadoop is the most common platform used here, although other alternatives are starting to emerge.
Input Data
Incoming data can come from a number of sources, and the following are examples of some of the tools that can be used to input data to platforms.
- External Databases: Databases that are not in the platform: Sqoop, Attunity Replicate (Qlik), etc.
- Message Queue: Apache Kafka, Apache Flume, and RabbitMQ.
- Web Service: Apache Flume, Apache Nifi.
- Input Files in Several Formats: Apache Nifi, Apache Flume.
- Log Files: Apache Flume, LogStash, and Fluentd.
Processing Data
Data can come in any format, and if it is necessary to keep data from interest parties before saving it into the platform, there are options available. Several tools and frameworks are used for this purpose, some examples are Apache Nifi, Apache Spark, and Apache Pig.
Store Data
After you have pre-processed your data, it will then need to be stored in a specific platform. Several tools can be used for this in conjunction with the requirements of the processing phase.
- The most common file systems for this are HDFS and Ceph.
- Common databases used for this are Apache Hive, Apache HBase, MongoDB, &Cassandra
- A common file used for Object-storage is S3
- Redis is commonly used here for caching
- For log storage and analysis, ElasticSearch is commonly used to store its data in the Data Lake platform.
ETL Procedure
In computing, the complete process is called extract, transform and load. Nowadays, with the huge amount of information processed in real-time, ETL has been reevaluated and sometimes these activities are done at the same time.
Since the new conception about data, where it does not matter to have duplicated information or inconsistent information, what does matter is the time used to do so.
So, if you can save time and transform data during the extraction phase, then by all means go for it. This will obviously depend on the problem that you are trying to solve, and the data being utilized in its required format.
If you would like to read more on big data you can do so here:
- https://towardsdatascience.com/breaking-the-curse-of-small-datasets-in-machine-learning-part-1-36f28b0c044d
- https://www.quora.com/What-are-the-best-tips-to-scale-Python-on-large-datasets-for-Machine-Learning
- https://machinelearningmastery.com/large-data-files-machine-learning/
- https://www.semanticscholar.org/paper/Heuristics-for-Sample-Size-Determination-in-Siddiqui/fa7a1c2e306b2aa2a4e9f8b15de7075246e1e0ba
- https://www.povertyactionlab.org/sites/default/files/resources/2018.03.21-Rules-of-Thumb-for-Sample-Size-and-Power.pdf
- https://machinelearningmastery.com/much-training-data-required-machine-learning/
- https://medium.com/business-data-quality-analyst/sample-size-for-cluster-analysis-72260a40e41d
- https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2447286
- https://machinelearningmastery.com/much-training-data-required-machine-learning/
- https://datascience.stackexchange.com/questions/13901/machine-learning-best-practices-for-big-dataset
- https://towardsdatascience.com/breaking-the-curse-of-small-datasets-in-machine-learning-part-1-36f28b0c044d
- https://pdfs.semanticscholar.org/262b/854628d8e2b073816935d82b5095e1703977.pdf
- https://www.bmc.com/blogs/data-governance-data-management/
Conclusion
If you are contemplating becoming a data scientist, a big part of your job will involve overcoming numerous issues before being able to make insights from the presented data. In saying that, it's important to remember to not be afraid to challenge yourself when accomplishing this.
The information is available for you, you just need to avail yourself of your Google search skills and to remember to be patient when doing so. The key here is to identify the problem, investigate the possibilities available, and filter the information available to help you make a decision.
As with most things in life, trying and failing is the best way to learn, so do not be afraid to fail here. Just pick yourself up and try again.


