
There is a feature in OpenAI that is sometimes overlooked but is very useful in terms of efficiency and cost savings: the batch functionality. This feature allows us to send thousands of requests to GPT at the same time and asynchronously wait for the results, saving up to 50% on generation costs when using any text model.
While this feature won’t help with real-time or synchronous results, it is ideal for handling a large number of requests and helps to avoid rate limits typically encountered with the regular completion API. Batch job delivery times vary, but they are never longer than 24 hours.
The batch functionality can be accessed through a convenient UI on OpenAI’s platform or via the API. In this guide, I will show you how to use the API with the Python openai library.
To send requests to the batch API, you will also need to use the Files API. Here are the high-level steps:
- Create your batch file with all your requests in the correct format.
- Upload your batch file to OpenAI.
- Create the batch job using the already uploaded batch file.
- Poll the batch job to check if it has finished.
- When the batch is finished, you have two options:
- If it was completed, you’re done! You can now download the results, including the output files and any error files if there are any.
- If it failed or expired, you should fix the batch files and try again from step 1.
Creating the batch file
The batch file must be a jsonl file, which means it has a JSON object per line. Each JSON object must include the following entries:
- custom_id → An ID for your request. This is important and must be unique because it will be used to match outputs to inputs.
- method → HTTP method of the request. Only POST is allowed for now, but it is a mandatory field.
- url → The OpenAI endpoint you want to hit with the request. This can be /v1/chat/completions, /v1/embeddings, or /v1/completions.
- body → The request itself. The structure of this object changes depending on the endpoint you want to hit. In the case of chat completions, here you can set the messages array and the different LLM configurations like the model, temperature, and max_tokens, among others.
For example, let's call this file batch_input.jsonl:
Upload the batch file
Now we upload the file to OpenAI storage using the Files API. Ensure the purpose parameter is set
There are some restrictions:
- The file can contain up to 50,000 requests.
- The file cannot be more than 100 MB in size.
If the file does not comply with these restrictions, you will be allowed to upload it, but an error will appear when creating the batch.
💡 Note: if you do not have the OpenAI python library installed, you can do it with pip install openai.
The response should be something like this:
Create the batch job
Once we have successfully uploaded the file, we can create our batch job using the file ID:
In the endpoint parameter, we must indicate the endpoint to be used for all requests in the batch. It should be the same as the one used in the requests of the batch file.
In the completion_window parameter, we must set 24h, as this is the only accepted value for now. This parameter specifies the time frame within which the batch should be processed.
The batch creation response is an object like this:
Check the status field, which will tell us if the batch has completed or failed. It should initially be in validating status. The batch job will first validate that the batch file is correct (i.e., all the requests are valid, and the size and number of requests are appropriate).
Getting the batch status
Once we have submitted our batch job, we need to wait until it is finished to get the results. To do this, we can retrieve the batch job to check its status:
The status can have several values, with the most important being:
- completed → The batch job completed successfully, and now we can retrieve the results.
- failed → The job failed (not the individual requests, but the batch job itself as a whole).
- in_progress → The batch job has passed validation and is still running.
Handling the Errors
If the status is failed, we must fix our batch file and try again.
We can check the reason for the failure under the errors field. Generally, it fails on batch field validation because we passed an incorrect field in a request or our batch file is too large or has too many requests.
Getting the results
If the status is completed, then we can retrieve the results.
A batch completion doesn’t mean all requests were fulfilled successfully; some requests may contain errors thrown by the chat completion API. For example, if we used the json_response output format but didn’t include the word JSON in the prompt, the chat completion API would throw an error.
So, we should get both the successful results and the possible errors.
To get the results, we must obtain the IDs of the generated output and error files (if they exist) and get their content from the Files API.
Getting the successful requests
And there it is, we now have all the results of our batch job. The outputs array will look something like this:
To get the GPT responses:
Getting the error requests
The error array will have this format:
To get the error messages:
Optional: Delete the uploaded files
Once we finish processing the results, we can delete the files from the OpenAI storage if we want to, taking into account that the storage limit is 100GB.
Conclusion
The OpenAI Batch API provides a powerful way to handle large volumes of requests efficiently, saving both time and costs. As a reference, here is a cost comparison graph of GPT-3.5 and GPT-4 handling requests through the chat completion endpoint using the standard endpoint versus the batch API. The comparison was calculated using 2048 input tokens and 158 output tokens:
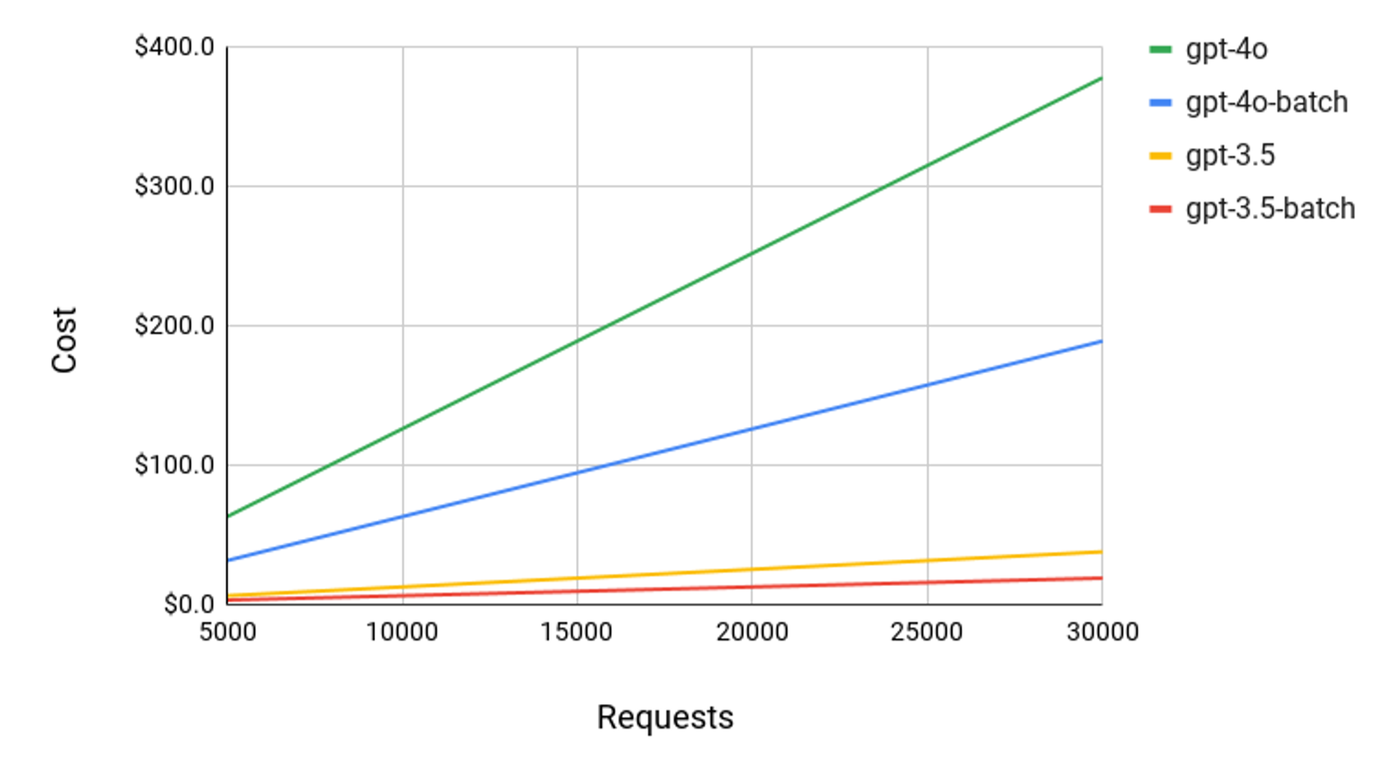
This guide has walked you through the entire process, from creating and uploading your batch file to retrieving and handling the results. By leveraging the batch functionality, you can overcome rate limits and process up to 50,000 requests asynchronously. While it is not ideal for synchronous requests or real-time applications like chatbots, it excels in scenarios where bulk processing is required.


