
Journals, blog websites, and companies with blog sections often face the need to classify their papers, articles, and blog posts. Classification serves various purposes, such as improving navigation, optimizing searchability, and enhancing SEO. This is where tags or keywords come into play, allowing us to succinctly summarize the main topics of a document with a few representative words.
But how can we select the appropriate tags? A valid approach to tagging is to use preselected tags and assign new articles or blogs to existing ones, preventing an unmanageable increase in the number of tags over time. Another question arises: should tags be chosen by the blog's author, the page's admin, or automatically inferred? The answer depends on the purpose of the tag. If it is purely informative, the author may have the best insights, while the admin is better positioned to understand the company's or website's SEO needs and strategies. However, an automatic process can be beneficial in both cases, either as a suggestion tool or as a reliable final result if the algorithm is trustable enough. In this article, I will explain how we address these two questions at Rootstrap using a topic modeling technique called LDA.
Rootstrap currently has a collection of over 250 blogs encompassing a wide range of topics, including technical, social, and marketing subjects. Given the substantial number of blogs, manual review of each one for decisions about the content and marketing strategies is impractical. To face this challenge, we used topic modeling to identify the most important topics and keywords, which we will explain in this blog’s first part. In a subsequent blog, we will show how we utilized OpenAI's GPT API, specifically GPT-4, to perform blog classification and assign relevant tags to our blogs.
Topic Modeling with LDA
Topic modeling is a Natural Language Processing technique that allows us to obtain the underlying topics of a text. LDA (Latent Dirichlet Allocation), is an algorithm which implements this technique. It considers that each document is composed of a mixture of topics in a certain proportion, with each topic represented by a collection of related words or keywords that frequently co-occur. Therefore, the more words associated with a particular topic appear in a document, the higher the probability that the document belongs to that specific topic. The number of topics has to be defined in advance
The Gensim package provides a Python implementation of LDA. It takes as inputs the documents’ corpus, a dictionary mapping each unique word to an ID, the desired number of topics, and the number of passes over the documents to achieve the final results, among other parameters. The document corpus is formatted as a bag of words, containing a list of word IDs with their corresponding occurrence counts.
Text preprocessing
To build the corpus, preprocessing is necessary for each document:
- Stopwords removal, including common language words that can introduce noise to the topics, such as prepositions, pronouns, auxiliary verbs, conjunctions, and even generic domain-specific words.
CODE: https://gist.github.com/santit96/49416987a3903a4b238e0de05dea5d45.js?file=remove_stopwords.py
- Strange symbols and characters (like punctuation, digits, and non-Unicode characters), and HTML tags present in the blog's text are eliminated.
CODE: https://gist.github.com/santit96/49416987a3903a4b238e0de05dea5d45.js?file=clean_symbols.py
- Lemmatization is applied to convert words to their root form.
CODE: https://gist.github.com/santit96/49416987a3903a4b238e0de05dea5d45.js?file=lemmatization.py
- The cleaned text is tokenized to extract unique words (unigrams) and form bigrams and trigrams if desired.
CODE: https://gist.github.com/santit96/49416987a3903a4b238e0de05dea5d45.js?file=tokenize.py
- Finally, the dictionary is created from the unigrams (and bigrams/trigrams) to assign unique identifiers to each word, and the bag of words (bow) is constructed.
CODE: https://gist.github.com/santit96/49416987a3903a4b238e0de05dea5d45.js?file=bow.py
With the bag of words and dictionary prepared, the next step is to determine the number of topics. This can be achieved by running the LDA algorithm multiple times with different topic sizes and evaluating a metric called coherence to evaluate their performance.
CODE: https://gist.github.com/santit96/49416987a3903a4b238e0de05dea5d45.js?file=run_lda.py
The final selection of the optimal number of topics is adjusted manually, considering domain-specific knowledge. In our case, from the coherence metric we obtained that the best number of topics was between 4 and 7. We finally chose 6 topics based on their sparsity and density, feeling satisfied with their representation.
Topic modeling results
Those resulting topics were AI, Marketing, Blockchain, Design, Development and QA. Here it is graphically the final result of the topic distribution:
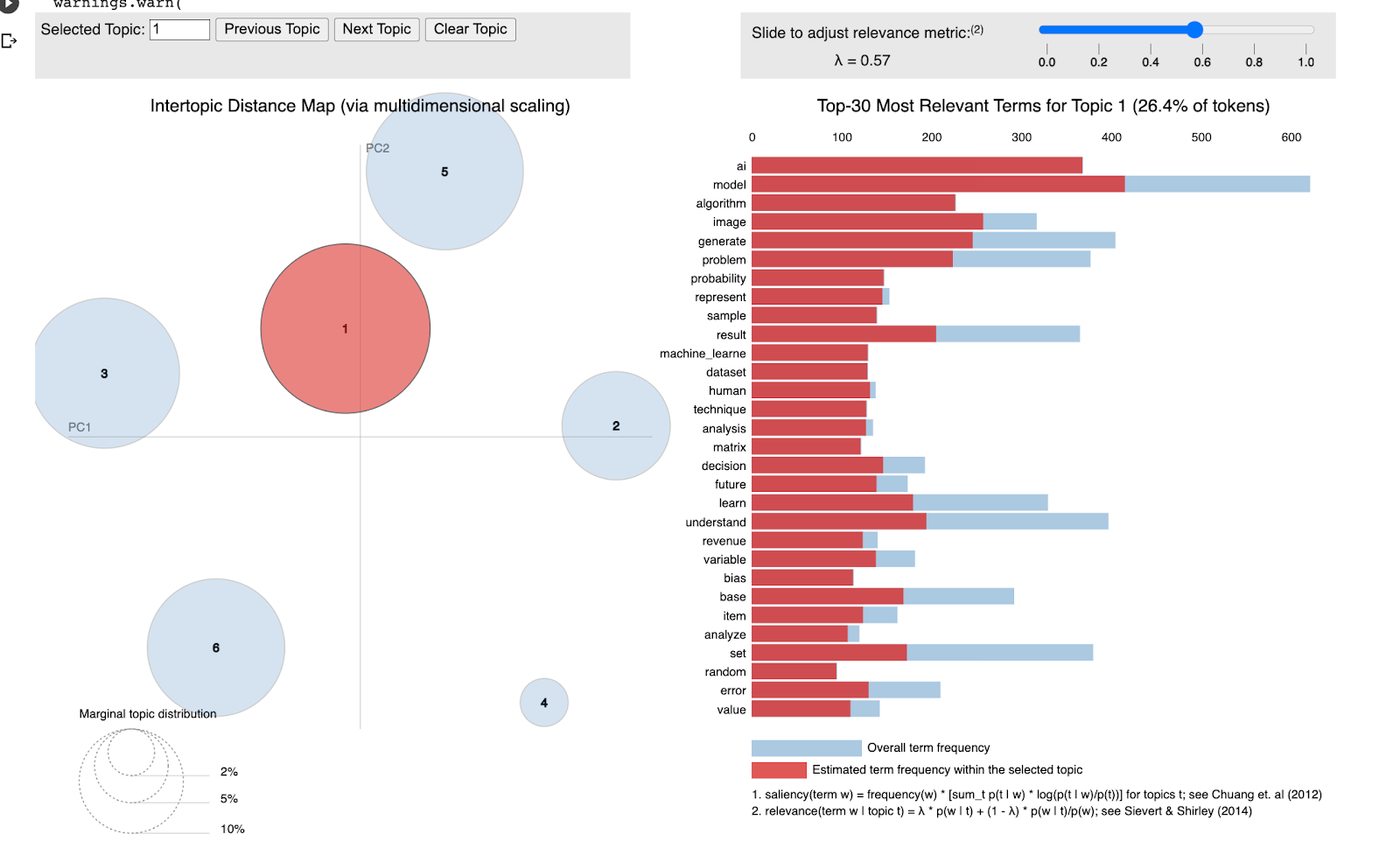
Every circle represents a different topic, the size of the circle is related with the amount of documents containing words from that topic.The words of the right are the relevant terms for the topics, the light blue bar represents the term frequency in all the topics, and the red bar represent the frequency of that term in the selected topic. In the image above, Topic 1 is selected, which we can see that is represented by ‘AI’ keywords. ‘AI’ seems to be the most representative word of that topic, it is not the most frequent word overall, but its frequency within that particular topic in relation with its overall frequency is the highest.
The image below shows the most prominent keywords in each one of the topics:

Manual adjustments
Later, we discovered that the QA topic included keywords related to DevOps, which was another important topic we wanted to include. However, when attempting to create 7 topics with LDA to specifically address DevOps as a separate topic, we failed. The seventh topic either resulted in an empty topic or a topic that was too generic. This could be because of the limited number of blogs and keywords about DevOps. As a solution, we opted to maintain the original choice of 6 topics and manually separate the DevOps documents from the QA ones.
Once obtained all the desired topic with their corresponding tags, what followed was a curation of the tags of each topic. Although the keywords obtained by LDA were fine, those were not necessarily the ones aligned with the company marketing strategy and SEO, thus a manual selection of those tags, which fit with those requirements, was made.
Summary
To sum up, this blog highlighted the power of LDA for blog classification and the significance of selecting appropriate tags. By using that topic modeling technique we could address the challenge of tag assignment, and through manual adjustments and curation, the optimal topics and tags were determined, aligning with marketing strategies and SEO requirements.
In another blog called “How to classify blogs using GPT-4”, we will discover how to leverage the power of GPT-4 to perform the blog classification into these tags.


