
Ensembles are a combination of several ML models in order to generate a better model.
Sometimes some models perform well for certain cases and in other cases, other models fit better the data.
Why not combine those models to create a more powerful model? Your predictions are going to be much more accurate!
There are 3 main ways of combining models:
- Baggin: the same model is performed several times changing the training dataset, the outputs are combined by averaging (prediction) or voting (classification). As an example, applying a Logistic Regression over 3 different training sets, then combine the results taking the class that is classified by 2 models.
- Boosting: consecutive execution of the model learn in sequence correcting errors that the predecessor model made. The goal is to improve areas of the data where the model makes errors. It is commonly applied in decision trees, for boosting trees each base classifier is a decision tree, connected as a sequence.
- Stacking: several models learn in parallel and finally are combined by averaging (prediction) or voting (classification). The idea is to combine different models into one, being able to consider different properties from the same training data. Finally, those models are combined to produce a final result.
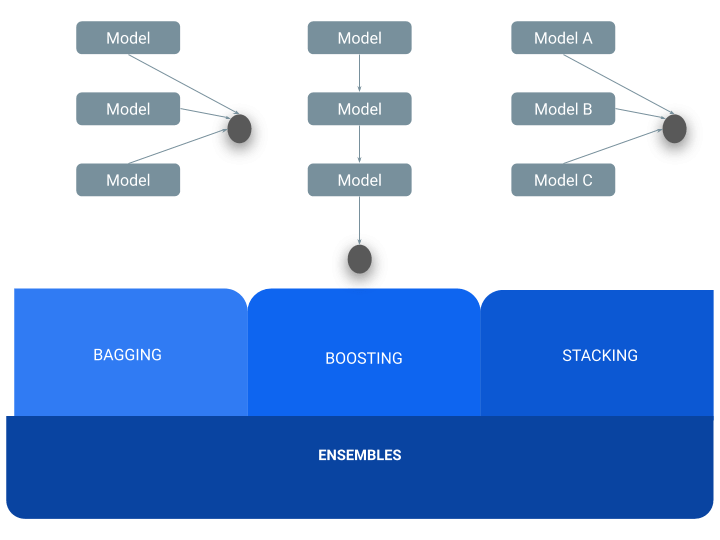
Ensembles models
Pros and Cons - Combination of Several ML models
While ensembles seem to resolve all the problems, they are not magic and they also have disadvantages. In this table advantages and disadvantages are presented. You might need to find a balance between them and decide if it is convenient to use them or not for your specific problem.
AdvantagesDisadvantagesEnsembles usually have a better prediction than a single modelIt requires more computational costEnsembles that can be performed in parallel are a fast way to improve the prediction, since different teams can work separately and execute in different environments, and then combine the resultsEnsembles that use multiple data sets require data to be collected and storedEnsembles that use different samples of the data help to avoid overfitting, since more cases are coveredThe ensembles might turn on into blackboxes, since it can get complex to understand the relationship between predictors and outcomes
When we want to resolve a machine learning problem, we aim to find the best model that best fits the data. Using ensembles, we can reach better performance and lower errors.
On the other hand, sometimes it is not necessary to add more complexity to the solution making it difficult to understand.


