
Database normalization is a fundamental process in relational database theory, aimed at enhancing data organization for optimal usability and clarity. By structuring data into tables, this process ensures that database outcomes remain clear and aligned with intended objectives. This guide delves into the concept of database normalization, its historical significance, and its relationship to modern data management practices.
The concept of database normalization can be traced back to E.F. Codd, an IBM researcher, who introduced the relational database model in 1970. Codd's pioneering work laid the foundation for what he termed "a normal form for database relations," which became integral to the relational technique. During the 1970s and 1980s, when storage costs were high, data normalization gained prominence as an efficient method for data organization. This was especially crucial as disk drives were expensive and efficient data storage was a pressing need.
Database normalization involves structuring data into tables with the goal of minimizing ambiguity and redundancy. This practice optimizes data integrity and facilitates streamlined data retrieval and manipulation. However, it's important to note that normalization may result in data duplication within the database and the creation of additional tables.
Database normalization rules
Database normalization rules are fundamental principles in relational database design. These rules guide the efficient structuring of data within tables to eliminate redundancy and ensure consistent data integrity. By organizing data into different normalization forms, such as First Normal Form (1NF) and Third Normal Form (3NF), databases become more efficient, manageable, and less prone to data anomalies.
Understanding and implementing these normalization rules is essential for creating databases that deliver accurate and reliable results while optimizing data storage and retrieval processes.
Most common anomalies in databases
- Insertion anomaly. There are circumstances in which certain facts cannot be recorded at all. For example, each record in a "Faculty and Their Courses" relation might contain a Faculty ID, Faculty Name, Faculty Hire Date, and Course Code. Therefore, the details of any faculty member who teaches at least one course can be recorded, but a newly hired faculty member who has not yet been assigned to teach any courses cannot be recorded, except by setting the Course Code to null.
- Update anomaly. The same information can be expressed on multiple rows; therefore updates to the relation may result in logical inconsistencies. For example, each record in an "Employees' Skills" relation might contain an Employee ID, Employee Address, and Skill; thus a change of address for a particular employee may need to be applied to multiple records (one for each skill). If the update is only partially successful – the employee's address is updated on some records but not others – then the relation is left in an inconsistent state. Specifically, the relation provides conflicting answers to the question of what this particular employee's address is.
- Deletion anomaly. Under certain circumstances, the deletion of data representing certain facts necessitates the deletion of data representing completely different facts. The "Faculty and Their Courses" relation described in the previous example suffers from this type of anomaly, for if a faculty member temporarily ceases to be assigned to any courses, the last of the records on which that faculty member appears must be deleted, effectively also deleting the faculty member, unless the Course Code field is set to null.
Normalization example
Concepts
Before we start digging into an example, we first have to understand some key concepts:
Keys
In SQL, a key is a column or a set of columns in a database table that is used to uniquely identify each row within that table. Keys are fundamental to maintaining data integrity and ensuring that the data in a database remains accurate and consistent. There are several types of keys in SQL:
Primary Key (PK)
A primary key is a unique identifier for each row in a table. It ensures that no two rows have the same values in the primary key columns, and it also enforces the uniqueness constraint. Additionally, a primary key column cannot contain NULL values. Each table can have only one primary key.
Foreign Key (FK)
A foreign key is a column or a set of columns in a table that is used to establish a link between two tables. It enforces referential integrity by ensuring that values in the foreign key column(s) match values in the primary key column(s) of another table. This helps maintain relationships between related tables.
Composite Key
A composite key consists of two or more columns used together to uniquely identify rows. This is often necessary when no single column can guarantee uniqueness.
Initial data
Assume, a library maintains a database of books rented out. Without any normalization in database, all information is stored in one table as shown below.
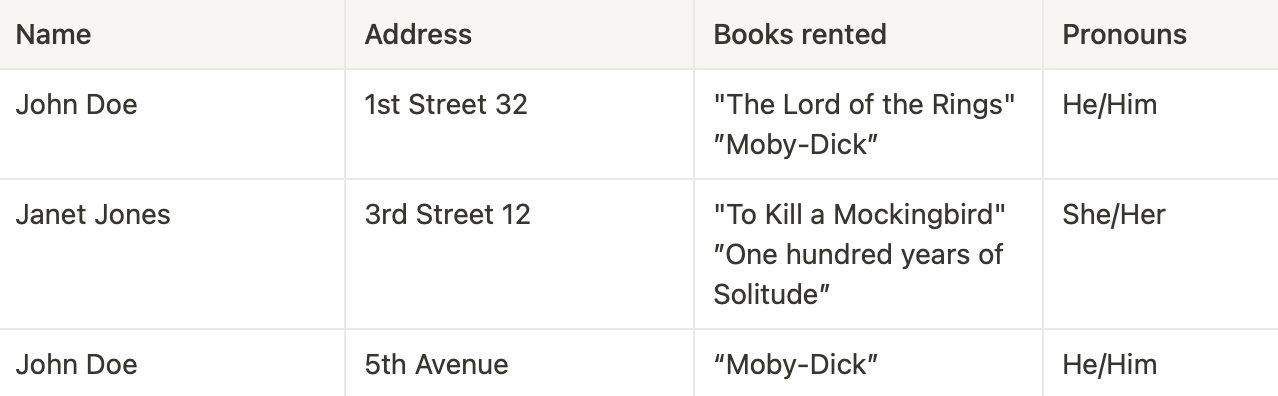
Here you see Books rented column has multiple values, let move it to First Normal Form
First Normal Form (1NF)
- Each table cell should contain a single value.
- Each record needs to be unique.
The above table in 1NF will look something like this:

Second Normal Form (2NF)
- Rule 1- Be in 1NF
- Rule 2- Single Column Primary Key that does not functionally dependent on any subset of candidate key relation
It is clear that we can’t move forward to make our simple database in 2NF unless we partition the table above.
Table 1:
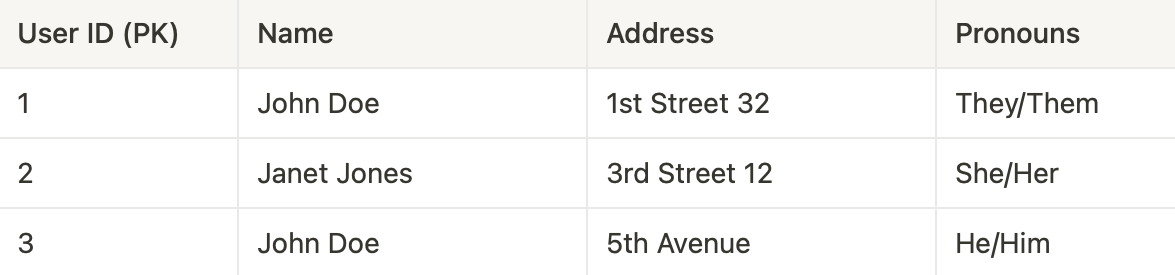
Table 2:

We've optimized our database structure for better organization. We've divided our initial table into two tables: Table 1, which holds user details, and Table 2, which stores book rental information.
In Table 1, we've added a crucial primary key column called "User ID." This key ensures that each record within Table 1 can be uniquely identified using user information.
In table 2, “User ID” is a Foreign Key that references the Primary Key of Table 1
Third Normal Form (3NF)
- Rule 1- Be in 2NF
- Rule 2- Has no transitive functional dependencies
What are transitive functional dependencies?
A transitive functional dependency occurs when modifying a non-primary key column has the potential to impact the values of other non-primary key columns.
Consider the Table 1. Changing the non-key column Name may change Pronouns.
To move our 2NF table into 3NF, we again need to create more tables.
Table 1:
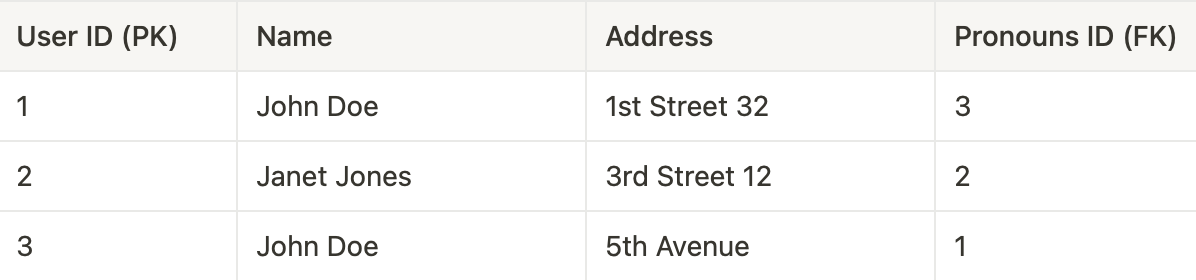
Table 2:
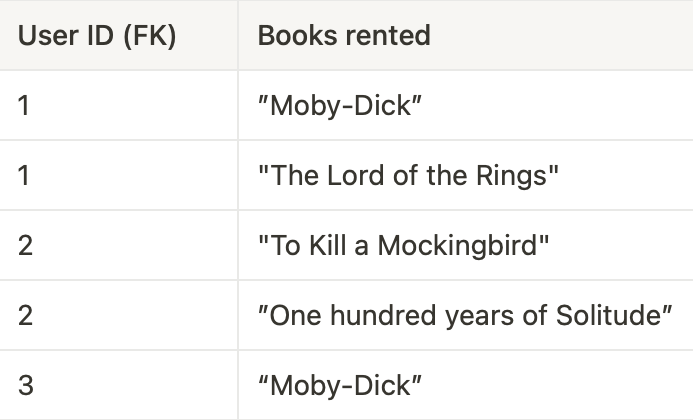
Table 3:

Our table is in 3NF as it doesn't exhibit any transitive functional dependencies. In Table 3, the primary key is Pronouns ID, and in Table 1, Pronouns ID serves as a foreign key referencing the primary key in Table 3.
At this point, our example has reached its highest level of normalization and cannot be further decomposed to achieve more advanced normalization forms in DBMS. Typically, more elaborate normalization efforts are required for complex databases.
There are two more Normal Forms that we can turn our database into, but these are not as common and follow this rules:
4NF (Fourth Normal Form)
If no database table instance contains two or more, independent and multivalued data describing the relevant entity, then it is in 4th Normal Form.
5NF (Fifth Normal Form)
A table is in 5th Normal Form only if it is in 4NF and it cannot be decomposed into any number of smaller tables without loss of data.


