
The type of data samples that populate our visualizations can add uncertainty to our results. Some common data displays like bar and pie charts work better than others for making that uncertainty understandable. This article explores how to understand our data samples and create the most suitable graphs for visualizing what they represent.
In general, the goals of data science are to understand data and generate predictive models that help us make better decisions. For a more thorough overview of data visualization, see “Data visualization and The Truthful Art.”
Know your datasets
In data analysis, we often deal with small samples, not a full population of data. The full set might be reduced by computational simplification or because only a small subset of a more complex data universe is available. In those cases, data scientists often create visualizations that neglect the real nature of their samples. Sometimes they aren’t even aware that their dataset is only a sample.
When we create analytics based on small datasets, uncertainty needs to be accounted for. But in many cases, that doesn’t happen because including uncertainty and statistical complexities can lead to far more complicated processes that slow down the overall analysis. But whenever we prioritize rapid iteration and exploration over statistical accuracy, we need to be aware that we’re doing so.
Visual data analysis and uncertainty: an old dichotomy
There aren’t many standard visualization techniques that embrace uncertainty in an intuitive way and make uncertainty ranges easily understandable. The examples in figure 1 demonstrate this issue with probability visualizations.
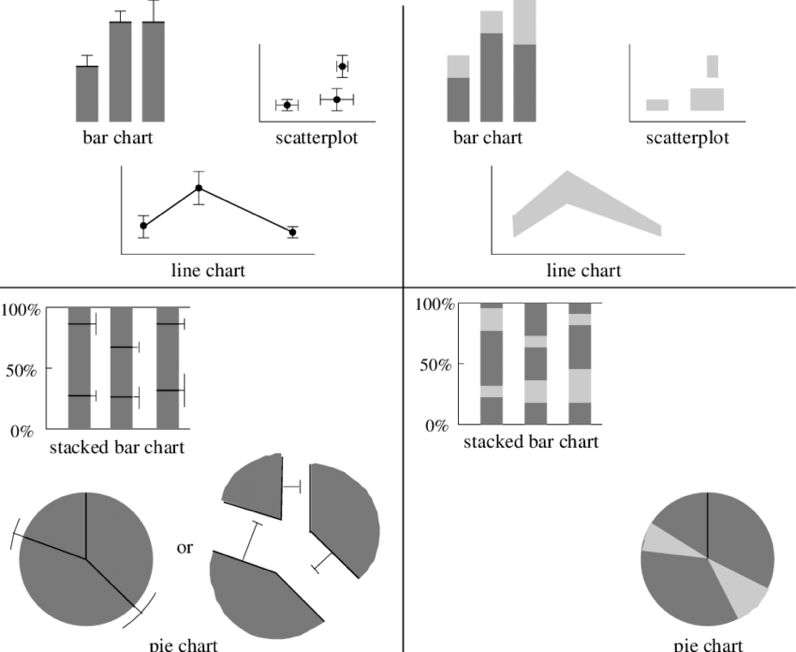
Figure 1
Issues with uncertainty
It’s trivial to compare the height of two bars in a bar chart. But it can be tough to compute the probability of a nearly overlapping set of uncertainty regions. Even experts trained in statistics make mistakes when they interpret confidence intervals.
Uncertainty must be computed with a different mindset. Instead of asking if A is greater than B, we need to ask what the probability is of A being greater than B. This fuzzy logic incorporates real-life uncertainty. Data visualization should align with this paradigm.
According to “Judgment under Uncertainty: Heuristics and Biases,” people tend to make wrong decisions when they analyze uncertain data (Tversky and Kahneman 1974). Our brain isn’t wired to deal with probabilistic data in an intuitive way. To untangle this problem, we first need to clearly visualize two basic things:
- Confidence intervals
- Sample size information
How to visualize uncertainty
The classical visualizations that we’re all familiar with aren’t great ways to create insightful displays of uncertainty. A good visualization doesn’t merely replicate data from tables or files. It displays relevant data in a visual format that reveals trends or relationships. When insights are successfully visualized, the viewer gets an “aha!” moment.
Even experts have difficulty with using confidence intervals for tasks beyond reading confidence levels. Although it’s complex, a correct representation of uncertainty helps us understand the risks and value of our decision-making process.
A practical example
When we work with samples, we can only estimate aggregated aspects of the data. Some examples are the expected average, sum, or count of a dataset based on the sample. We can infer a distribution on this expected value. According to “Interactive Data Analysis with CONTROL,” we can use the Central Limit Theorem to estimate error bounds based on these estimators (Hellerstein et al. 1999).
The chart in figure 2 is based on a sample from a large dataset of sales. The confidence interval is 95%. So we expect the mean value for sales in 1995 to be somewhere between 49,000 and 51,300.
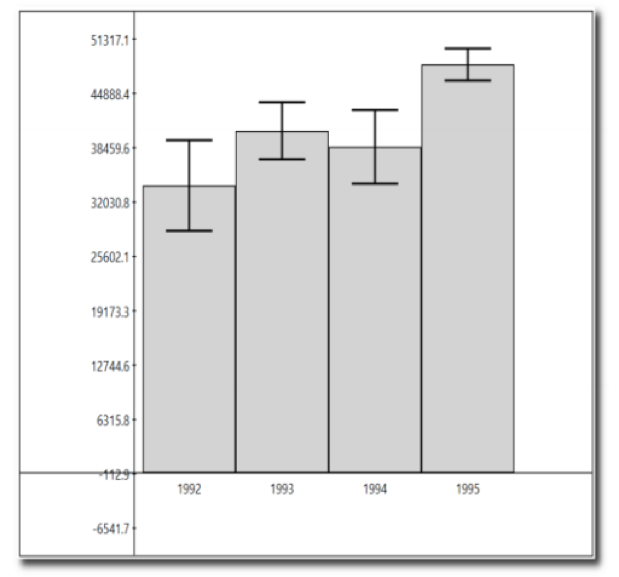
Figure 2
These tasks are often done during the exploratory phase of data analysis:
- Find the minimum and maximum.
- Sort values.
- Compare values.
In a regular chart, without uncertainty, these tasks are as easy as comparing values or checking if bar A is bigger than bar B. However, when we embrace uncertainty and probability distributions, it’s not so simple. In those cases, we need to perform statistical inferences based on the given distributions. Again, a change in mindset is required to deal with this fuzzy logic. That is, we can’t ask if a certain fact is true. We can only estimate the likelihood of a fact being true.
Next, we’ll explore two visualization techniques: uncertainty bar charts and ranked lists.
Uncertainty bar charts
In “Sample-oriented task-driven visualizations: Allowing users to make better, more confident decisions,” the authors discuss five tasks based on uncertain bar charts (Ferreira et al. 2014):
- Compare a pair of bars.
- Find maximum or minimum.
- Compare values to a constant.
- Compare values to a range.
Figure 3 compares a white bar to the others: dark blue means certainly below, and dark red means certainly above.
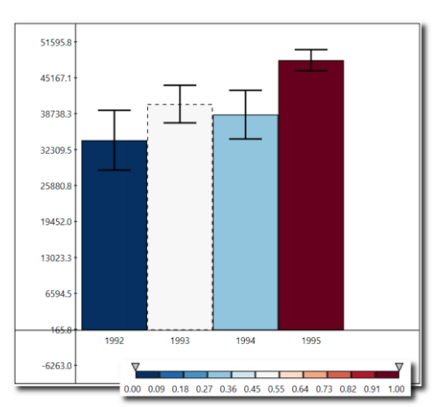
Figure 3
Figure 4 displays the maximum and minimum. The two pie charts show the probability that any given bar might be the maximum or minimum value.
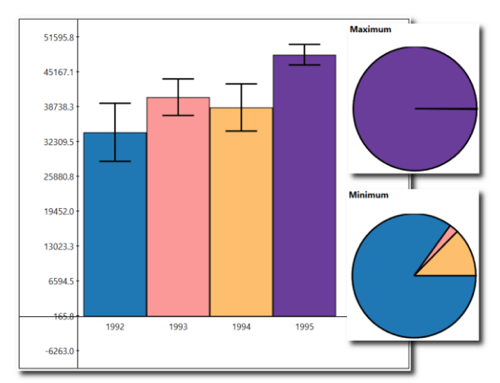
Figure 4
Figure 5 compares a bar to a fixed value. In this case, it’s easy to calculate the probability of a chart being higher or lower than a fixed value.
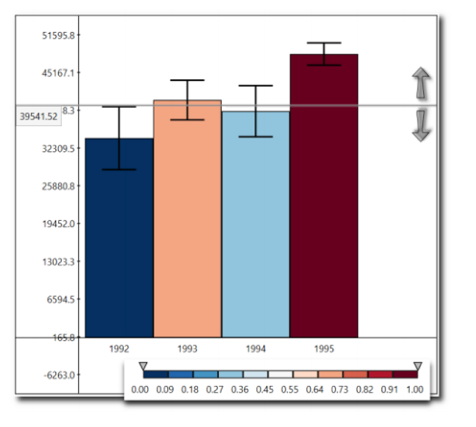
Figure 5
In figure 6, dark colors are likely to be inside the range, and light ones are outside the range.
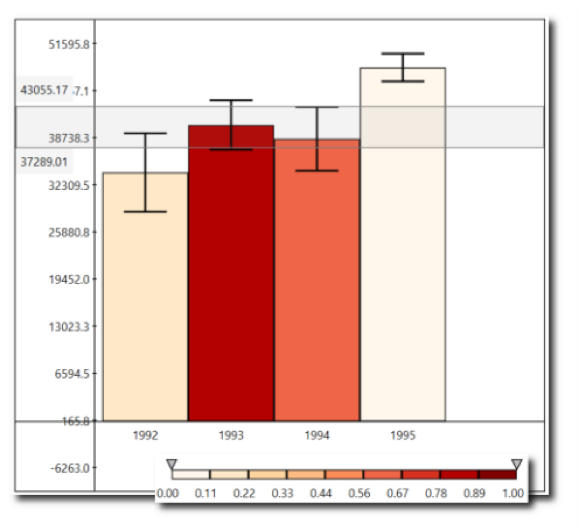
Figure 6
Uncertain ranked lists
Regular ranked lists represent sorted elements. They often show only the top few bars of a large set of variations. As an example, we might want to visualize the top five events that occur most often in a server log. To get that information, we need to sort all the values and truncate the list. This method works well when the number of possible values is too big to display.
They are useful in a non-stationary environment, where new values can become more relevant over time. This list type tends to stabilize, but it supports rapid change.
Uncertain ranked lists have a partial order. We’re certain that some items will be greater than others. But we might be uncertain about other pairwise relationships. In their visualization article (Ferreira et al 2014), the authors explore two tasks based on sorting a list:
- Identify which items are likely to fall at a given rank.
- Identify which items are likely to fall between a given pair of rankings.
Ferreira et al (2014) also designed a two-step algorithm to compute uncertainty:
1- As a heuristic, the Central Limit Theorem is used to estimate confidence intervals based on the count, standard deviation, and running average of items we’ve seen so far. With this technique, the authors create one distribution for each aggregate on the chart.
2- The Monte Carlo method is used to compute probabilities, leaning on the calculated distributions.
Each task is represented by a predicate. That is, D1 is likely to be greater than D2. From each distribution, Ferreira et al (2014) repeatedly draw samples and evaluate the predicate against the samples. They repeat the process about 10,000 times. The probability of an event is the fraction of those iterations where the predicate is true. This computational approach calculates only approximate probabilities. But if we run it numerous times, it produces accurate approximations.
Figure 7 is a representation of the same data displayed with ranked lists instead of bar charts.
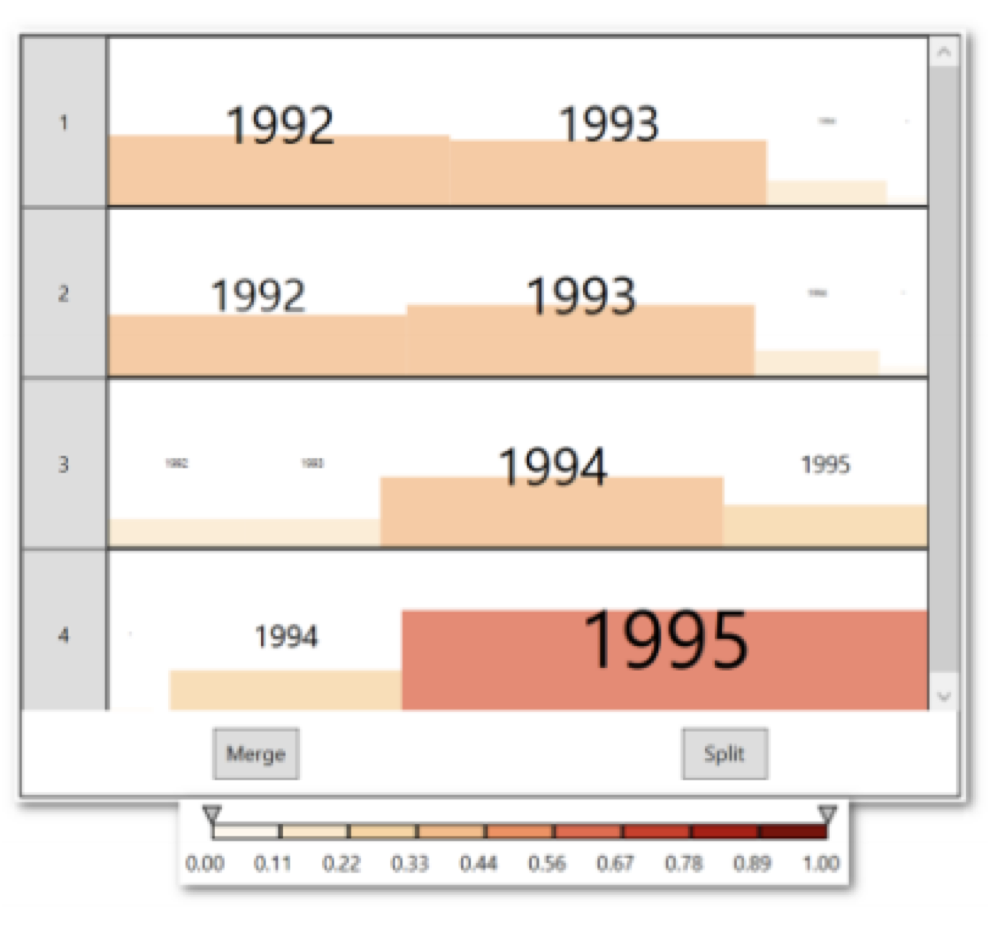
Figure 7
We can conduct both tasks by using this kind of visualization:
1- Identify which item is likely to fall at a given rank (top 3 in figure 8).
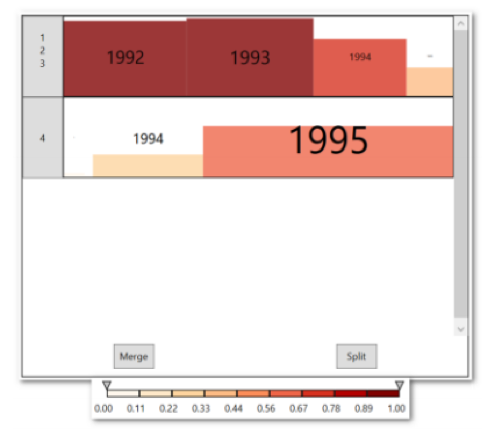
Figure 8
2. Identify which items are likely to fall between a given pair of rankings (figure 9).
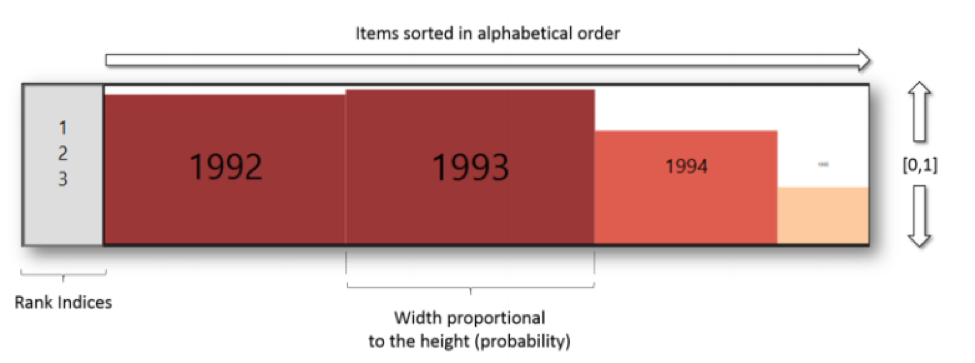
Figure 9
Height, width, and color are proportional to the probability that this item will fall in this bin. It’s almost certain that 1992 and 1993 will fall in the first three items. 1994 and 1995 divide the rest.
Conclusions after user testing
The Ferreira et al (2014) study suggests that bar charts lead to more intuitive and insightful analysis. So users are less likely to make mistakes when they interpret data. However, enhancing bar charts with task-specific annotations might help users make even better decisions about their samples.
References
Ferreira, N., Fisher, D., and König, A.C. (April 2014). “Sample-oriented task-driven visualizations: Allowing users to make better, more confident decisions.” Available here.
Figueroa, A. (2019) “Data visualization and The Truthful Art.” Towards Data Science. Available here.
Hellerstein, J., Avnur, R., Chou, A., Olston, C., Raman, V., Roth, T., Hidber, C., and Haas, P. (August 1999). “Interactive data analysis with CONTROL.” IEEE Computer, 32(8), 51- 59. Available here.
Olston, C., and Mackinlay, J. (July 2002). “Visualizing data with bounded uncertainty.” IEEE Symp. on Information Visualization (INFOVIS 2002). pp. 37–40. Available here.
Tversky, A., and Kahneman, D. (September 1974). “Judgment under uncertainty: Heuristics and biases.” Science, 185. 1124–1131. Available here.


