
This article outlines a mental framework to organize our work around Data Quality. Referencing the well-known DIKW Pyramid, data quality is the enabler that allows us to take raw data and use it to generate information, starting from raw data.
In this piece, we’ll go over a few common scenarios, review some theory, and finally outline some advice for anyone facing this increasingly common issue.
Why?
The amount of data being generated every second is almost impossible to comprehend. Current estimates say that 294 billion emails and 65 billion WhatsApp messages are sent every single day, and all of it leaves a data trail. The world economic forum estimates that the digital universe is expected to reach 44 zettabytes by 2020. To give you an idea of what that means, take a look at the byte prefixes and remember that each one multiplies by 1000: kilo, mega, giga, tera, peta, exa, zetta.
Not all of this data is created equal. It comes in different forms, and at first, it’s just noise. Raw data doesn’t have any implicit pattern or sense to it. It needs interpretation to be useful. Software can help us interpret data by organizing it in different ways, either structured or unstructured.
But software is made by people and it operates in real life. We know what that means: people make mistakes, the world changes, programs have bugs, and data has quality problems. Always, always, always.
Bad data quality leads to inaccurate and slow decision-making. This doesn’t happen all at once, as data quality tends to deteriorate over time. Like everything else, it follows the second law of thermodynamics: total entropy of an isolated system can never decrease over time.
We can’t avoid this. But we can create processes to identify the problems, process and improve data quality, and make sure we add value at every stage of the process. Remember that in working with data, our goal is to generate information, not simply collect random noise.
Where are we?
The first step is understanding where we are and where we want to go. What are our metrics? What’s our business goal? How good is our data?
For this, we have to understand the following criteria of data quality:
- Completeness: Data is considered complete when it meets the expectations. We may have optional data, but lack of completeness means that we’re missing the information that we do want.
- Consistency: Data is considered inconsistent if we have contradictory or conflicting information about the same thing in two or more different places.
- Timeliness: Is the information available when it’s expected? For example, log reports of an error being accessible 5 hours after the error happened is not acceptable.
- Integrity: This concept speaks to well-designed data and systems. As an example, in a relational database, it means no orphaned records or lack of linkages between semantically linked data.
- Accuracy: This means that what we store should be accurate enough to reflect real life values. If we store the wrong birthday for a person, there’s an accuracy problem.
- Standardization: This dimension is still subject to discussion, but in my opinion, decisions taken during database design should be consistent and follow standards (either using common standards or your own variations). In relational models, the different ways of normalization are standards. Often times, you end up consciously denormalizing data (to increase performance, as an example), but that decision should be taken using objective arguments that can be incorporated into your own standard. Other details like date formats are matter here.
How do we measure these dimensions?
Unfortunately, there’s no single answer or silver bullet to this question. My recommendation is usually to create an algorithm based on the reality of the project. The algorithm can take inputs and give a score to each dimension, for example, between 0 and 1. There are multiple ways to process large chunks of data and calculate these scores, or you may even choose a representative part of the database to process. Heuristics and common sense are extremely valuable here. Doing it programatically makes sure that you can run the same tests over and over again, comparing the results.
Ideally, in a professional process, you should come up with an output like the following:
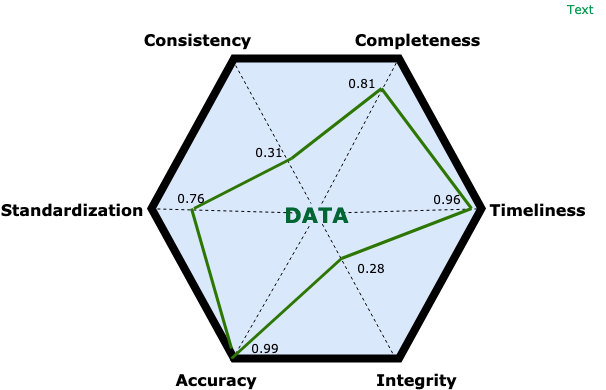
Data Score Diagnosis
After taking this crucial first step, we can start assigning a weight to each dimension. Weighting is important because it makes data more relevant to our real-world situation: some data quality criteria may be important to achieving our business goals, while others may not matter much to us. This analysis, done in conjunction with stakeholders, should help highlight the pathway to an informed decision. It should relate to your priorities and clarify your most important next steps.
What’s next?
After narrowing your focus, you can decide if you have a real problem. If you do, you can work on each dimension one at a time, employing whatever techniques best suit the situation.
One example of this could be using Python’s Panda library to read and process either from files or a relational database, create transformations that will increase one of the data quality dimensions, then push the fresh data again to the original database.
Another approach could be trying to mitigate future data problems by tracking down the problem to an algorithm in your code, or even realizing that your database design itself needs adjustments.
We’ll explore some of these techniques in a following article. But as a conceptual model, this should serve as the basis for any systematized data quality efforts.
References
- Russell .L. Ackoff, “From Data to Wisdom,” Journal of Applied Systems Analysis 16 (1989): 3–9.
- Harland Cleveland, “Information as Resource,” The Futurist, December 1982, 34–39.
- Arkady Maydanchim, “Data Quality Assessment”, September 15, 2007
- Bernard Marr, Forbes, “How much data do we create every day?”
- Jeff Desjardins, WeForum, “How much data is generated each day?”


