
Some days ago the React Summit Remote Edition gathered tons of people behind the screen with the promise of putting together popular speakers around the React Community like Kent C. Dodds and Guillermo Rauch among others, but one talk especially caught my attention, React Query: It’s Time to Break up with your "Global State”! by Tanner Linsley. In it, Tanner talked about two pain points that I had frequently with React, which were how to handle asynchronous information in the global state and how to restructure my code to be less repetitive and not force async data to follow synchronous flow. In this article, I'll explain in more detail which is the problem with the global state and how React Query solves it in an efficient-scalable way.
The problem with global state
Libraries like Redux, MobX and even Context API provided by React are based in the Global State pattern, which means that to avoid prop drilling and sharing data between the components in different hierarchy levels, and have one single point to read and write from the components(making it easy to store data used across the app), the entire application exposes a global variable called global state.
This pattern has many advantages, but the problem lies in the different types of data that potentially has the global state in our applications. These data can be internal information about our application, like for example if the navbar is open or not, or information that has ownership with another source, for instance, the user information like his name, age, etc, that is provided by backend and can be modified in the frontend. The two types of data mentioned above can be classified as a client state and server state.
The main difference between each is the server state has two sources of truth, the backend, and the frontend. This causes the server state to synchronize all the time to prevent that its information is not out of date. As we know, this is not performant at all and it wouldn't be a good practice to request information all the time(image putting a spinner every time you do a request), for that reason we need some way to show the old information and at the same time update it with the new information on the background every so often. This is a very difficult task if we try to do with Redux or the other tools that I mentioned before because we have to find a way to resolve cache management, background update and other cases that require a little bit more of implementation when merging old and new data such as pagination or infinite scroll.
What is React Query and how it solves these problems?
React Query is a library that with 2 hooks and 1 utility (only 5kb!) provides an easy and scalable way to fetching, caching, and updating asynchronous data in React.
Before jumping off to the code and seeing some examples I'd like to introduce how React Query models the server state.
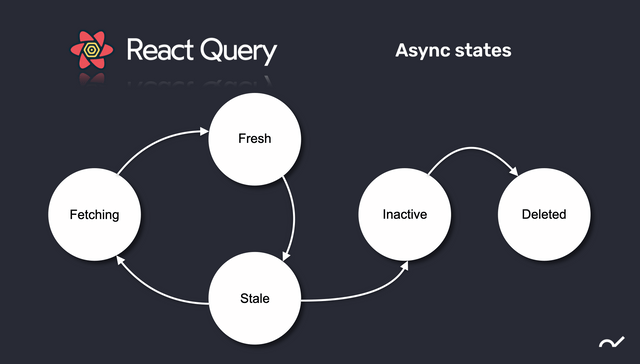
In the image above, we can see the different states for the server state information, let's explain what is the meaning of each state:
- Fetching: This is the initial state and occurs when the data is fetching from an outsource, typically the backend.
- Fresh: On this state, the information is the same on both sides, this is the desired state of our application because it implies that we don't need to re-fetch the information. On the other hand, this state lasts a short time because in most cases when you're fetching information, this information immediately is potentially out of date.
- Stale: Represents the out of date data that the app is currently using. This happens because the frontend has old information and needs to re-fetch it from the backend, or the backend is not updated because the frontend didn't send the new information to the backend yet. This state is particularly important as long as we want to be in the fresh state again.
- Inactive: React Query has a garbage collector for managing cache on the browser, this state in some manner indicates to React query that if the data is not being used in the application, it will potentially be deleted after a while. This is a great feature of React Query, because we want to persist the recent information to not fetching data all the time and improve the speed/UX of our interfaces.
- Deleted: This happens when the data was inactive for a certain period of time and it's deleted from the cache. This timeout can be configurable locally for each query or globally.
With this approach, React Query handles the asynchronous information of our application clearly, allowing us to scale and maintain our code in a better way.
Introduction to React query API
Although React Query has only two hooks, it is highly configurable in all aspects, from the retry delay time of the queries to the set maximum time of inactive data in the cache. But let's start with the most basic API that is well documented in their repository
CODE: https://gist.github.com/nsantos16/7f71e979ed3c884755906c9dbdee1436.js
This hook provided us the status of the fetch (loading, error, or success), and data and error if they are defined. Up to this point is a pretty normal hook for fetching information, but as we see the query is related to a key (in this case [.c-inline-code]movies[.c-inline-code]), this is a unique-global key that is used for associate the query information between the components, in this way we can re-use this hook to use the same information in anywhere of the DOM tree. If you follow the classic redux action-reducer cycle for fetching data, these hooks will save up a lot of repetitive code.
Among other things, React Query also allows us to filter the information with a simple system.
CODE: https://gist.github.com/nsantos16/99d85d896256be0006f3d55cab8c5595.js
And also, to contemplate the case that the client-side alter the server state React Query introduces the concept of mutations(well known for GraphQL developers), let's make a quick example.
CODE: https://gist.github.com/nsantos16/3ac5eac3d607b89f2b11a56821390462.js
With [.c-inline-code]onSave[.c-inline-code] function we're re-fetching the information on the background while immediately change the specific information(in this case the new movie) in the user interface.
Manage cached data
Saving data that we fetched and how we save it is an important aspect of our application, it improves the sensation of speed in our interfaces, and avoids hitting the backend all the time. One of the more important aspects of React Query that sets it apart from other libraries like SWR is the strategy and mechanism to manage the cache. For managing cache, there are a lot of alternatives and strategies we can adopt, and in most cases, it depends a lot on the problem we need to resolve. For general cases, and more particularly for frontend cases, like pagination, infinite scroll, or just showing information, stale-while-revalidate strategy is an excellent choice. This strategy consists of, as the name says, revalidating the information (fetching) while the old data is shown to the user. Let's put an example to make it clearer the movies example,
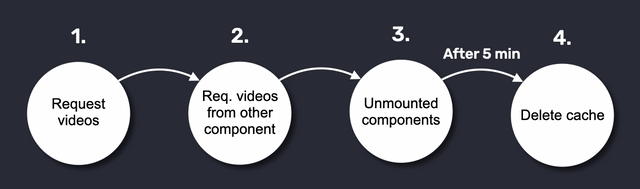
let's say I have a video streaming platform with home, explore and user settings pages, in the image above we can see a classic flow of requests in this kind of application, when:
- The user enters on the platform at the home page, all the movies are requested (Loading spinner is shown to the user)
- The user goes to explore page to see the catalog of movies divided by genre, then the movies that we requested before are showed while React Query revalidates on the background (Any loading spinner is shown to the user and the response is immediate)
- The user goes to the settings page, then React Query detects movie data are not used in the application so pass to the "inactive" state
- After 5 minutes (or the time that you configure on the query), React Query removes the information from the cache
Final thoughts
React Query is an excellent tool with an incredible API that opens the conversation around how and why we use synchronous patterns for asynchronous data and how this impacts the way we build our applications today.


