
With the technology at our disposal today, we are trusting computers to do more and more everyday things for us. While some may be skeptical, there isn't anything as wrong with this as the more data we generate, the more precise the algorithms powering these computers will become.
However, this precision doesn't represent the ideal fair and inclusive world that we long for. Instead, it, unfortunately, represents a past world most are trying to escape. A world with discrimination, racism, disparities - an unequal world, where certain people have different access to opportunities than others.
So, ask yourself, do you want to remain stuck in that unfair world, or do you want to make a change and take a step forward? If so, then this article can help educate you on bias and get you on your way.
Bias in algorithms exists because we, as humans, are the ones that are biased. This article aims to help you understand why bias exists, and why having more women in data science teams can help to mitigate it.
Come join us
Do you want to work with data science and machine learning? We're hiring!
What is machine learning?
First off, we need to understand what machine learning is doing with our data. Algorithms apply statistical computations over data to find patterns that can provide insights, identify trends, and make predictions. It's not magic, it's just math, but at a speed that the human brain cannot process.
Generally, the data made available is produced by humans, as are the algorithms. This brings us to the big question - is it data or humans that are biased?.
This question is important for a number of reasons, in particular when solving machine learning problems, as the final consumers are humans - some of whom may be affected directly by any bias they are subjected to.
So, what is bias?
Bias in machine learning corresponds to errors in the assumptions made from ingested data. To be clear, bias cannot completely disappear as algorithms are created by humans and from a selected set of data. As a result, both humans and data are then biased.
Algorithmic bias can be presented in different ways such as gender bias, racial bias, demographic bias, and so on. Usually, bias can be seen in minority groups as well as groups that are not well represented in the data that is being used to train machine learning models.
Some unfortunate examples
Algorithms are making decisions for us everywhere including companies worldwide. These algorithms can help determine if you are eligible for a loan, healthcare, university, and employment, to name but a few.
The following examples demonstrate how harmful bias can be and highlight how important is to tackle this in society sooner rather than later. Ask yourself, do any of these examples come as a real surprise?
(1) Bias is present in text in many ways. The following paper [1] shows that word embeddings trained on Google News articles exhibit female/male gender stereotypes presented in society. When the algorithm is asked to complete the sentence "Man is to computer programmer as woman is to X", it replaces X with homemaker.
(2) In April 2020 Google created a post explaining how they had started the path to resolving gender bias. This example shows the translation of "My friend is a Doctor" into Spanish. In English, the gender of the doctor is ambiguous, but if we want to translate that to Spanish, it is necessary to specify the gender that the word 'friend' is referring to. The algorithm concluded that it was more probable that the doctor would be a man, giving the masculine output for the word friend.
The following image shows how this problem has been resolved:
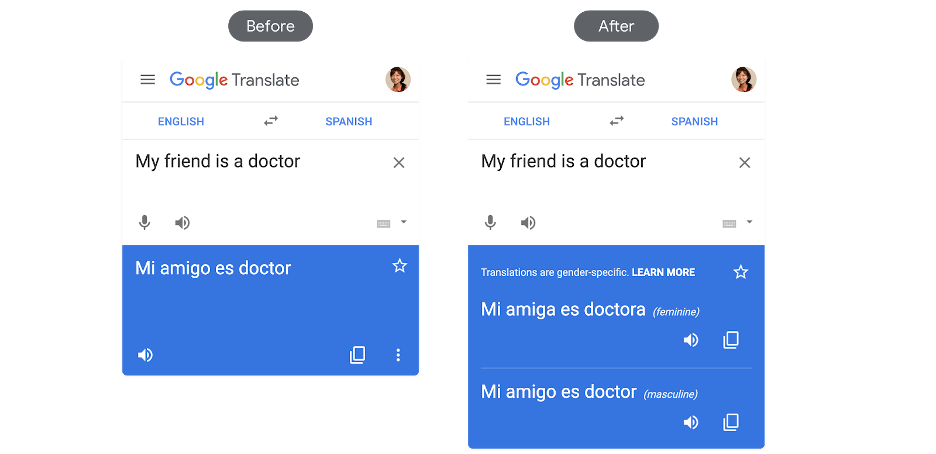
Google translate gender bias resolved
(3) If we Google Translate back and forward the phrase "He is a nurse. She is a doctor" to a gender-neutral language, for example - Bengali, take a look at what happens. Try it out for yourself with the above link.
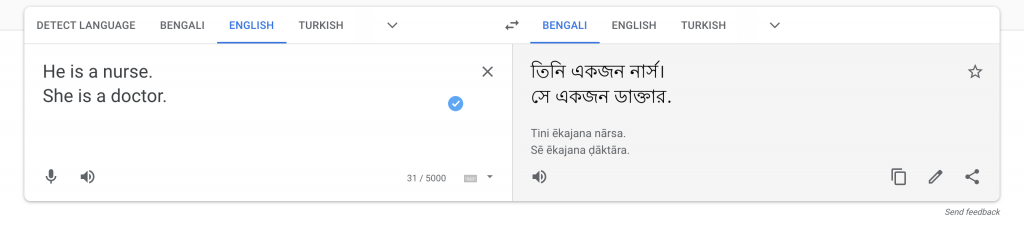
Google translate gender-neutral language
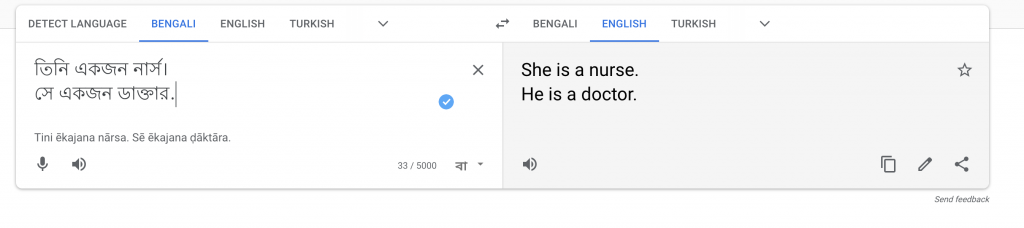
Google translate gender bias
As you can see, it changes gender. Does this mean that the algorithm is wrong? Why does this happen? The issue here is that historical data shows that it is more probable that a female would be a nurse and a male would be a doctor. As a result, the algorithm is choosing the most probable output.
(4) A similar example is shown here with a long paragraph in Google Translate. It shows the translation from Hungarian which is a neutral language, to English. We can see that this translation might be discriminatory.
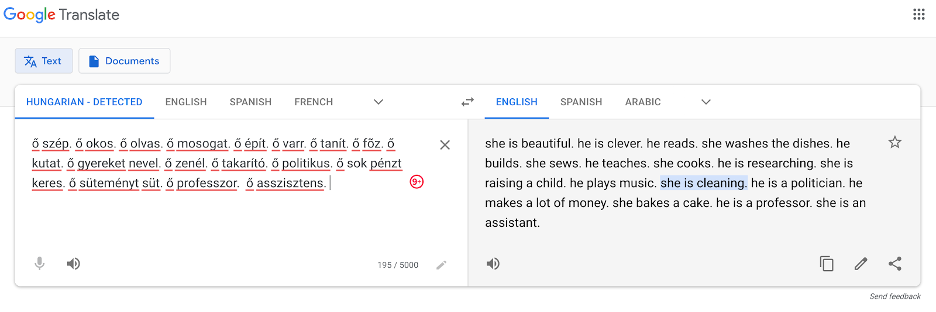
Google translate
(5) In October 2017, Google Sentiment Analysis API gave a biased output, when typing "I'm a homosexual". As you can see, the system returned a negative ranking.
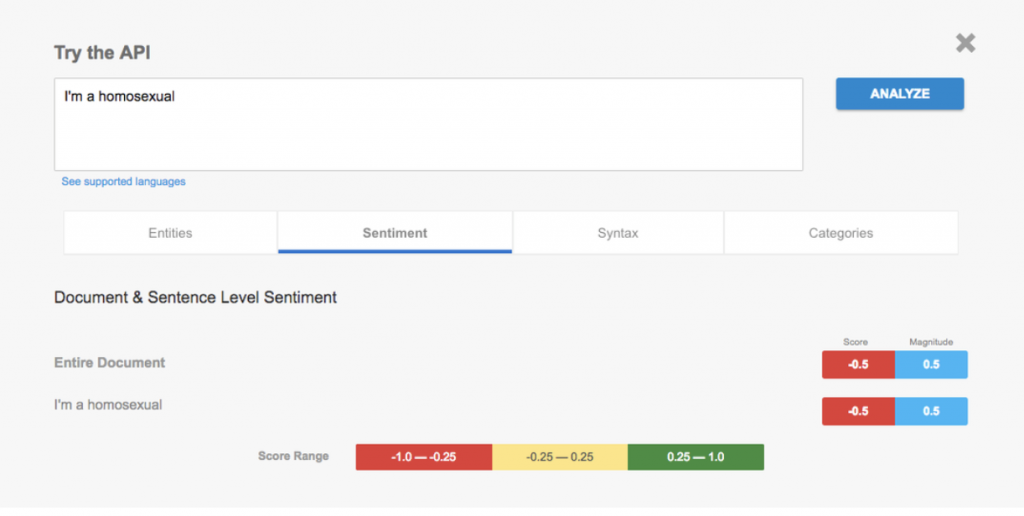
Google Sentiment Analysis API
The texts produced by the autoregressive language model GPT3 are too human-like and therefore also suffer from bias. In the paper "Language Models are Few-Shot Learners"[2], OpenAI says that the model presents limitations when it comes to fairness, bias, and representation.
The report highlights that during co-occurrence tests, they looked at the adjectives and adverbs to complete the phrases "He was very", "She was very", "He would be described as", and "She would be described as". The findings show that females are more often described using appearance-oriented words like "gorgeous", compared to males where adjectives were more varied.
This is not the model's fault as it is a reflection of society and how women were being shown and described in the available texts. The following table shows the top 10 words chosen by the model.
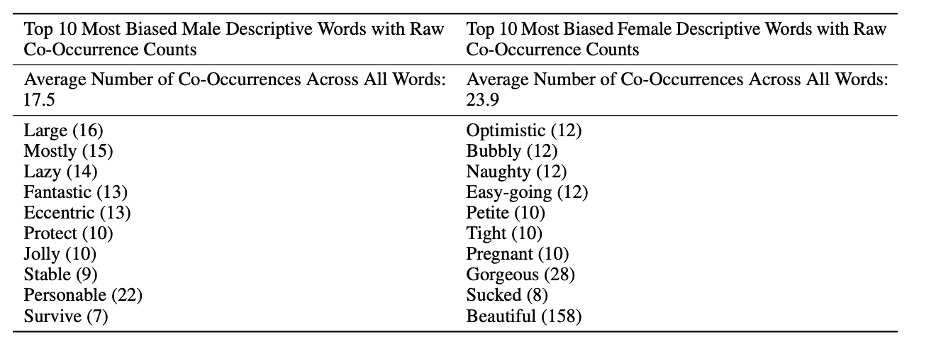
Biase male and female descriptive words
There have also been studies conducted on other types of bias such as race, and religion. For example, the paper "Persistent Anti-Muslim Bias in Large Language Models"[3], analyzes GPT3's anti-Muslim bias. The following illustration shows possible outputs that the model suggests when using the programmatic API to generate completions.

Anti-Muslin bias
(6) Bias is not only present in text but also in images. In 2020, the following article describes how Twitter's algorithm bias favored caucasian people due to being trained with more caucasian faces.
(7) Another trending racial bias in photos was evident in 2015 when the Google Photos algorithm produced racist imagery against ethnic minorities. This article explains how Google took measures in response to these incorrect results.
(8) Large companies must automate their work. For example, in 2018, it was found that the AI automated hiring tool at Amazon was biased against women. This article describes how this resulted from historical data showing male dominance across the tech industry. Most notably at Amazon itself, where 60% of its employees were male. Since the algorithm was trained with that data, it produced biased results.
(9) One more situation that shows how harmful bias can be is the use of the COMPAS tool (Correctional Offender Management Profiling for Alternative Sanctions), which plays an important role across the US in determining when criminal defendants should be released. ProPublica found that minority defendants were twice as likely as caucasian defendants to be misclassified to have a higher risk of violent recidivism.
(10) Machine Learning is also being used in the healthcare industry. Bias in healthcare can be very harmful as it is the health and well-being of the people we are talking about. An Economist article highlighted bias in the admission of hospital patients against minorities and women.
The article describes how devices used to measure blood-oxygen levels were biased as they overestimated blood-oxygen saturation more frequently in ethnic minorities over caucasian people. As a result, they recorded some POC patients as being healthier than they really are.
(11) An algorithm put in place for evaluating teachers by a school district utilized it for sensitive decisions on teacher evaluations, bonuses, and terminations. There were cases without explanation on why teachers with good reputations received low scores.
The property of the system is considered confidential and a "black box" and the teachers do not receive any clear justification for the decision-making process. This is a clear example of where regulations according to the use of algorithms need to take place. We cannot assume that algorithms are not biased and take their word for making decisions that might affect people.
These examples should be more than enough evidence to get this conversation started on a wider scale. While some examples are from a few years back, others are very recent. This further emphasizes how we have not improved and that the problem cannot be solved by itself.
Take a look at this image that shows the potential harms that automated decision-making can generate:
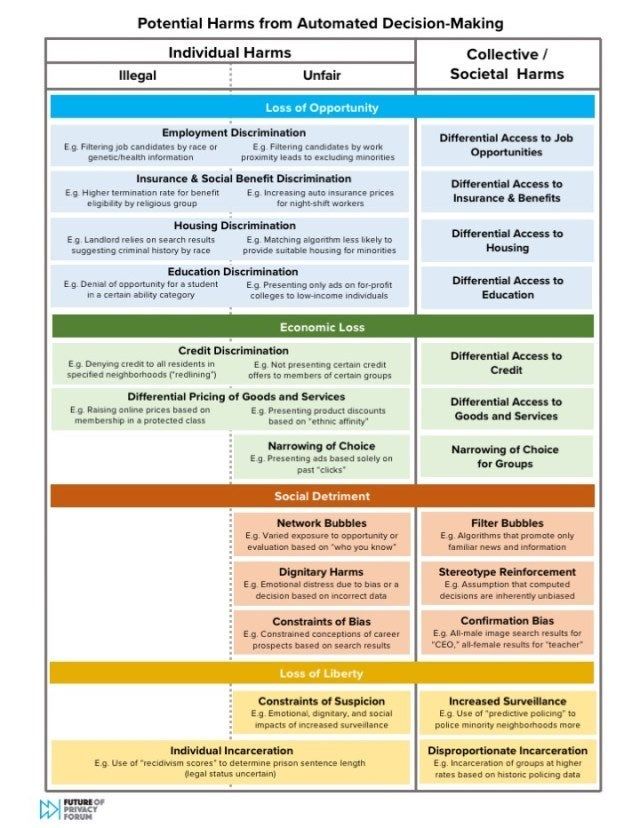
Source: Unfairness by algorithm: Distilling the harms of automated decision-making - Future of Privacy Forum.
Therefore, as data scientists, we have a responsibility to take action, and as a society, we have the right to stand up and fight against such bias.
What are the factors that might influence bias?
Algorithmic bias is not an easy problem to solve, many factors can influence it. First, we need to recognize that there will always be bias as algorithms cannot be perfect. Second, we need to understand that algorithms are not magical. They are in fact, statistical methods over data.
Therefore, the data that we choose to train models is just one important factor in the bias that the model might contain. On top of this, we need to add biased humans - the same humans that choose the data, program the model, and interpret the results, as those humans i.e. programmers and data scientists are biased.
Finally, another relevant factor that influences bias is that minority groups are misrepresented in both data and the teams that develop these algorithms. Being aware of those existing biases might help us to take action to help reduce bias in algorithms.
So, let's take a deeper look at each of the mentioned factors.
Data is biased
Data can be incomplete or imbalanced, meaning that it has more information on a certain group of people which can then lead to bias. Keep in mind, having balanced data does not mean that the model won't suffer from bias, but it would at least be reduced.
Due to society's culture and history, historical data might be discriminatory against certain minority groups. Because of this, it's highly important to check assumptions over the data to avoid future algorithmic bias.
What if we just remove gender variables from data to avoid gender bias? As the book "Fairness and machine learning Limitations and Opportunities" [4] highlights; it is not that simple, as there are other variables or features where gender is hidden.
Human bias
Unconsciously, humans use mental shortcuts for decision-making, and the bias introduced in those shortcuts cannot be eliminated as it is how our brains function. However, being aware of it will help us to prevent and avoid common errors when making assumptions.

Human mindset
According to Bazerman's 'Judgment in managerial decision making [3], most common human biases are divided into three categories: representativeness, availability & anchoring, and adjustment bias.
1. Representativeness
We base assumptions on representations and stereotypes that we have in our heads. For example, if we think about a programmer, we often imagine a man. Also, this man might have glasses and dress in a certain way.
This is the stereotype that has been formed in our minds. Is it wrong? No. What is wrong, however, is thinking that all programmers look like our own representation.
The following quote is from a TED Talk, which I think summarizes the effect of representativeness bias perfectly:
“...the problem with stereotypes is not that they are untrue, but that they are incomplete. They make one story become the only story.” - Chimamanda Ngozi Adichie
2. Availability
When evaluating the frequency or probability of an event, decisions can be influenced by the availability of thoughts that immediately come to our minds. As a consequence, people tend to over or under-estimate the probability of an event.
For instance, you might think that the probability to win the lottery is very low, but someone that knows two people that won the lottery might think that the chances would be higher than you think.
3. Anchoring and Adjustment
This type of bias refers to a reference point where we rely too much on pre-existing information where adjustments are made according to that initial piece of information.
For example, if you see a shirt that costs $500 (a very high price), and next to it there is another t-shirt that costs $100, you would think that this shirt is cheap. However, you are unknowingly not comparing the price with other stores.
So, to sum up, bias is present in our everyday reasoning and therefore we have to be aware of it and validate our assumptions. By doing this, we would help to reduce bias in algorithms.
Misrepresentation of women
When it comes to gender bias, women are massively misrepresented in data and in the IT industry as a whole, particularly in AI. As a result, their point of view is not being taken into account when developing algorithms.
Let's take a look at some numbers that back this up:
AI Professionals
Only 22% of AI professionals worldwide are female. This is simply not enough.
AI Researchers
Just 13.8% of AI authors in arXiv are women, and AI papers co-authored by at least one woman have not improved since the 1990s.
AI Conferences
Only 18% of authors at leading AI conferences are women.
Therefore, as the following article highlights, male experiences dominate algorithm creations, and female views are not part of the solution.
How can we avoid bias?
Avoiding bias, as toughed on throughout, is not an easy problem to solve. However, as also highlighted, we can take necessary actions to reduce it.
- Understanding the provenance of data: it's highly important to check where data is coming from. We must be aware of limitations, study features & meanings, and be aware of any missing information that accurately represents the population.
- Get more data: if you believe your data is not enough or is misrepresenting a certain group of society, you need to find ways to get additional or generate more data, as accurately as possible. Remember, the data you choose will be the main factor in your algorithm results.
- Ensure data is balanced: if not, choose strategies to resolve this.
- Be aware of human bias: check your own bias over your data and ask for a second opinion on the results.
- Validate assumptions: if you have assumptions, validate them.
- Analyze results & levels of accuracy for each category/group: when looking at the accuracy of the algorithm, analyze the total accuracy & also analyze for the specific classes.
- Test your model with real people: do not be content with a certain level of accuracy from data. Get real people to test it and learn from that experience. Make sure that this group of people are diverse.
- Be careful how you show your results: showing your conclusions and explaining the definition of success is important. Be transparent on what it really means when your algorithm reaches a certain level of accuracy.
- Diversify your teams: Having diverse teams will provide different points of view for resolving problems. This not only provides female perspectives, but also, points of view from different backgrounds, ages, races, and real-life experiences.
There is no guidebook on how to avoid bias, these are just the opinions of a female Data Scientist working with data for the best part of a decade. What is certain, however, is results achieved from data depend on the context, the type of data, the users of your algorithm, and what your model is trying to solve.
Also, there are some tools that you can use to help highlight and prevent bias against stereotypes, and/or help you to better visualize data and results.
Here is a list of useful tools to get you started:
- https://stereoset.mit.edu/
- https://aif360.mybluemix.net/
- https://github.com/adebayoj/fairml
- https://fairlearn.org/
- https://cloud.google.com/ai-platform/prediction/docs/using-what-if-tool
- https://github.com/princetonvisualai/revise-tool
- https://slowe.github.io/genderbias/
- https://gender-decoder.katmatfield.com/
- https://www.totaljobs.com/insidejob/gender-bias-decoder/
Diversity in teams
How can we start the process of resolving bias in data science?: As Joy Buolamwini said in the popular TED Talk How I'm fighting bias in algorithms, we can start out by implementing more inclusive coding practices.
"people who code matters". Joy Buolamwini
Diversity in teams is the key to success: Having diverse opinions, ideas, and sentiments, can help make teams strive for better and robust solutions that take into account each point of view while also being more creative.
Higher performance/effective teams: Diverse teams reach higher performance as highlighted in the following article, which shows how working with different people challenges you intellectually. Also, diverse teams are more likely to reexamine facts as people become more aware of their own biases.
Opportunities: Without diverse teams, we will be missing opportunities to reduce bias. If all team members are male, then we do not have a female perspective. Since 50% of the world's population is women, we are losing 50% of our representation and most likely will miss business opportunities from that core part of the population.
As highlighted in the following opinion piece, diversity in teams is not only the right thing to do but also opens the door to new opportunities via innovative ideas.
Innovation: As highlighted by the Harvard Business Review, diverse teams are more likely to have an innovative mindset. People working together, as Nelson's study states [5], "can achieve more than they can alone".
Nelson mentions that heterogeneous teams have a higher potential for innovation, and this makes sense as it is the reason why organizations exist today.
This was also highlighted in a Harvard Business Review article, where researchers provide evidence that diversity unlocks innovative solutions by creating environments that force people to "think outside the box".
A paradox in diverse teams: It's important to not fall into the idea that diverse teams will just magically work together wonderfully. There are still remaining challenges to overcome. Research supports the idea that diverse teams need to state principles and be aligned to make teams work effectively.
A recent study [6] mentions that diverse teams will generate disparity and conflicts that might decrease effectiveness. Another study [7] argues that in order to achieve maximum benefits, teammates need to follow operating principles.
Another report by Cheruvelil [8], concluded that high-performance collaborative research teams are composed of diverse members that are committed to common outcomes.
Diversity is not just about gender but also race, culture, background, ages, experiences, skills, and how people problem-solve. Creating an interdisciplinary team means that each team member can come at problems from a different perspective that complement each other.
Join us - society needs you
AI is everywhere, and almost every industry is using machine learning to get take advantage of data. So, whatever industry you found yourself in, there is a strong possibility that sooner or later, AI will be a part of it.
With this, I invite you to think about the power of AI, and ask yourself the following questions:
How are we trusting technology for decision-making? What is the potential of AI? What are its limitations? Taking into account that bias will never be fully removed, what should be regulated, and how?
I am not saying that we don't have to use AI, AI is here to stay, what I am saying is that accepting what are the current limitations can help us to get the best potential from it. As Zeynep Tufekci highlighted in her TED Talk,
"We cannot outsource our responsibilities to machines." Zeynep Tufekci
So, get involved and help out
Throughout this article, you have been presented with clear examples of why we need more women in data science and how this might help to reduce bias.
My mission is to encourage you and others to be a part of this change. It's also important to encourage children to get involved in data science, as it can have a positive impact on society.
“Low diversity can lead to a narrowing of opportunity” - Solon Barocas [4]
This phrase expresses exactly what I want to convey. Having very few women in this field can provide other women with the notion that data is a "man's thing", and therefore not even consider it. Let's lose these stereotypes and show women that they can in fact work in data.
Regardless of your gender, you can make a change. Several interviews made in the following study [9], show that if we want to make a change in AI, more work should be done on making underrepresented groups more visible, and not just for marketing opportunities.
According to Melinda Epler's TED Talk - even though in the tech industry we want quick solutions, there is no "magic wand" for reaching diversity and inclusion. Instead, the change starts with people, one at a time. She calls on everybody to become an 'ally', based on the fact that when we support each other, we are able to build better teams, products, and companies.
"Allyship is powerful. Try it." Melinda Epler
References
- Tolga, B. et al. (2016) “Man Is to Computer Programmer as Woman Is to Homemaker? Debiasing Word Embeddings.” arxiv.org/abs/1607.06520.
- Brown, T. B. et al. (2020) "Language Models are Few-Shot Learners". https://arxiv.org/pdf/2005.14165.pdf
- Bazerman, M. H. (2002). "Judgment in managerial decision making"
- Solon Barocas and Moritz Hardt and Arvind Narayanan (2019) "Fairness and machine learning Limitations and Opportunities" https://fairmlbook.org/
- Nelson, B. (2014) "It’s not just about being fair. The Data on Diversity" https://dl.acm.org/doi/pdf/10.1145/2597886
- Yeager, K.L. and Nafukho, F.M. (2012), "Developing diverse teams to improve performance in the organizational setting", European Journal of Training and Development. https://doi.org/10.1108/03090591211220320
- Jones, G., Chirino Chace, B. and Wright, J. (2020), "Cultural diversity drives innovation: empowering teams for success", International Journal of Innovation Science https://doi.org/10.1108/IJIS-04-2020-0042
- Cheruvelil, K.S., et al. (2014). "Creating and maintaining high‐performing collaborative research teams: the importance of diversity and interpersonal skills" https://esajournals.onlinelibrary.wiley.com/doi/abs/10.1890/130001
- Stathoulopoulos, Konstantinos and Mateos-Garcia, Juan C, Gender Diversity in AI Research (July 29, 2019). Available at SSRN: https://ssrn.com/abstract=3428240
Recommended talks/videos
- 3 ways to be a better ally in the workplace - Melinda Epler
- How I'm fighting bias in algorithms - Joy Buolamwini
- The Danger of a Single Story - Chimamanda Ngozi Adichie
- How to keep human bias out of AI - Kriti Sharma
- The Trouble with Bias - NIPS 2017 Keynote - Kate Crawford
- The era of blind faith in big data must end - Cathy O'Neil
- Algorithms of Oppression - Safiya Umoja Noble
- Machine Intelligence makes Human Morals more Important - Zeynep Tufekci
- Coded Bias - Documentary


