
To all who may be interested, did you know that you can generate images using AI? It's true, and this might be helpful for you in so many fun ways.
These types of AI-powered models can help with generating images for blogs, album covers, printing wall paintings for our room or desk, generating NFTs, and much more!
To bring you quickly up to speed we will explore the following in this article:
- How generative models work
- How to change styles of original images
- How to add colors to an image
- How to work without any input image
- How to restore old photos
- How to create an image from a sketch
- How to use text-to-image models
Come join us
Interested in working with AI technologies? We're hiring!
Generative Models
The work of a generative model involves the distribution of data to see how likely a given example is. There are different types of generative models available, and here we will break down the most popular for generating high-quality and innovative results.
Generative Adversarial Networks (GANs)
Generative modeling refers to an unsupervised learning method that automatically discovers patterns in inputs, that are then used to generate similar outputs. GANs reach the generative model by dividing the problem into 2 networks; the generator and the discriminator.
The generator aims to generate new images, and the discriminator classifies them as “real” or “fake”. With this method, the algorithm selects the images that seem more “real”, meaning that it is more similar to the original data.
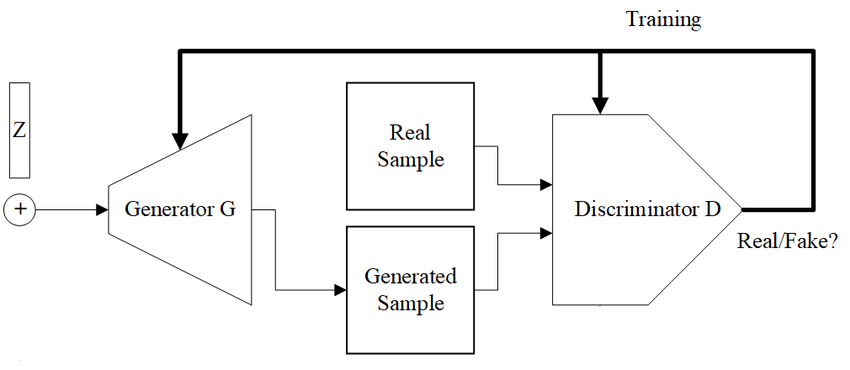
Generative Adversarial Networks (GANs) - Image source
Variational autoencoder (VAE)
An autoencoder is a neural network that compresses data in an attempt to reconstruct it from the resulting representation.
VAE differs from common autoencoders by the method it uses to compress data, via a multivariate latent distribution.
In the following image, the ´code´ section refers to the method used for the compression.
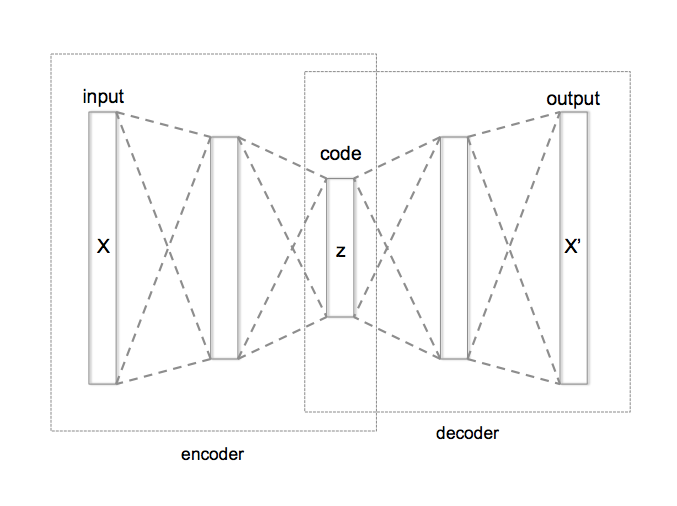
Variational autoencoder (VAE) - Image source
Diffusion models
Diffusion models are another type of generative model that can generate high-quality images. They can produce a higher quality of work than GANs when synthesizing images.
Diffusion models add noise to the data while removing details in steps before the neural network then tries to reverse the corruption (denoising).
As a result, there are different algorithms that can be used as well as a lot of open-source tools. We will take a look at some of these and show some examples that have been generated using these tools.
Changing the style of an original image
There are tools available to change the style of images, for example, Instagram filters. In the following example, we can see two tools that generate a new image from a given one while changing the original style.
GoArt
GoArt is designed to create NFTs in an easy way by transforming your original photos into paintings. With this tool, you don't need to be an expert to get into the NFT world, and with just a few clicks, you will have a ready-made NFT.

GoArt

Magenta
Magenta is an open-source research project that explores the role of machine learning as a tool in the creative process. They released a paper describing a method to allow real-time stylization using any content/style from a second image.
As we can see in the below example, by having two images (original and style), we can create a new image with the content of the first, and the style of the second. You can find the code for this here.

OriginalStyleResultMagenta


Deep Dream
Created by Google, Deep Dream uses a convolutional neural network (CNN) to visualize patterns it learns from images to create a ¨dream-like¨ and psychedelic appearance. Check out this Google Colab to generate similar images.

Deep Dream

You can also use the Deep Dream Generator tool, and best of all, you don't need any programming skills to use it!
Deep Dream

Adding color to an image
DeOldify is an open-source tool used to colorize black and white images. With the following examples, the first is a picture I took of my room in sepia, and the other is a photo of fresh tomatoes and basil.

DeOldify



In addition, amazing results in restoration can be found in the Palette model, which uses diffusion models to perform image colorization, inpainting, and uncropped images.
No need for an input image
Interestingly, there are algorithms that do not need any input image, as they are trained with a set of images that can generate new images. These can be faces, animals, landscapes, abstract art, and much more.
Generating new faces
A well-known example of this is thispersondoesnotexist.com, which uses GANs to generate new faces from people that do not exist. This can be useful for creating content without any cost, and you don't need to pay anyone for their photo.

Generating new faces
ImageNet
Big Generative Adversarial Network (BigGAN) is trained on ImageNet with a resolution of 128x128. In this notebook, you can generate samples from a list of categories.
ImageNet is an image database, where free data is available to researchers for non-commercial use. If you would like a deeper understanding of how it works, check out this paper.
In the below example, we generated images from one category. For these images, we used the ‘umbrella’ category.

Generated umbrella images
Interpolation
Interpolation allows you to generate images by combining two different categories and showing intermediate images while transforming an image from one category to another.
The following examples show interpolation between samples. In these images, we are using a tiger shark, Galeocerdo cuvier, and abubble.

Interpolation
Image restoration
Image restoration is the operation of removing noise from an image. It consists of making the reverse process when applying a blur to an image. The function is called Point Spread Function (PSF).
Restoring old photos
The Bringing Old Photos Back to Life paper proposes to restore old photos that suffer from degradation through the use of a deep learning model.
The model works very well for resolving multiple degradations mixed in old photos, such as scratches, noises, and blurriness.

Restore old photos

Sketch to image models
We can now create an image from a sketch by simply drawing a few lines before AI can finish completing it and give it a real high-quality attractive taste.
GauGAN
Gaugan is a model that takes semantic segmentation as an input and generates a realistic photo as an output.
Here is an image generated from a simple drawing (left), highlighting the quality of this model.

GauGAN
Text-to-image models
With a Text-to-image model such as GuaGAN2, we can generate images directly from a text prompt.
GauGAN2
The GuaGAN2 model supports text-to-image generation. For example, by typing ‘sunset at the mountains,’ you can produce the following type of images.

Gaugan2


You can play with this tool here and generate your own images using either segmentation or text.
VQGAN+CLIP
VQGAN+CLIPis a mix of two machine learning architectures CLIP and VQGAN. This tool generates images based on a given text.
VQGAN means Vector Quantized Generative Adversarial Network and combines Convolutional Neural Networks with Transformers. It's trained with a set of images and applies transformers to understand text inputs.
CLIP (Contrastive Language–Image Pre-training) is trained to determine from a given set of captions which one fits best with a given image.
This model was released by OpenAI and you can find the code at this repo, as well as the useful paper “Learning transferable visual models from natural language supervision”.
The following image example was derived from the Prompt “a dog in mars”. Pretty cool stuff here.

Dog in mars
DALL-E
DALL-E is a neural network that creates images from text captions for a wide variety of concepts. It works as a transformer language model that receives both the text and image as a single stream of data.
This model is trained using the maximum likelihood of generating all of the tokens, one after another.

Generated imagesPeople dancing at a partyDogs in loveBeautiful flowers around a lakePrompt DALL-E


GLIDE
The newest model in image generation is GLIDE, a diffusion model created by OpenAI. Check out this paper that highlights their investigation and the code for the model. Their model has been trained on 3.5 billion parameters.
Here is the output it obtained frim the prompt ¨an abstract painting of a monkey¨. As we can see, the bigger image maintains the quality when using this method.

GLIDE

Conclusion
Throughout this post we looked at just a few open-source projects that you can play with, and there are many more, so you won't get bored any time soon.
The best part is you don’t need any programming skills to generate images with AI. So, try out some of the tools and have fun!
Interested in learning more about the powers of AI? Check out our write-up on how to generate music with AI!



{kind=link}
{kind=link}