
Here at Rootstrap, our Machine Learning Engineers are committed to creating awareness of correct waste classification to help the environment. Their determination to make an impact led to the creation of 'RootTrash', an internal AI-powered app to help us recycle correctly.
We teamed up with Universidad de la República, an Uruguayan Public University to start the development of the app, and partnered with Abito, an Uruguayan recycling company that promotes revaluation of waste by facilitating the classification at source for recycling and composting.
Our University team started by classifying two classes - non-recyclable and recyclable. This initial model was simple and reached good accuracy. The next step was to extend the classifier with more classes, following Abito’s classification system.
These classes consisted of:
- Compostable items
- Paper & Cardboard
- Recyclable items
- General Trash
- Plastic
Adding these extra classes was a challenge for the group as they not only had to develop the machine learning model but also had to finish building the app within a quick timescale.
The team worked hard and reached an initial high accuracy of 80%. This version of the model was based on ResNet50 adding these layers at the end; AveragePoolingLayer, Flatten, and Dense layer with Relu activation.

Students from Universidad de la República
ResNet50 is a Residual Network - a convolutional neural network (CNN) that operates with 50 layers. The network is trained with images from the ImageNet database. It classifies 1000 objects from a wide range of broad categories, such as pencils or animals. The input size of the network is 224 x 224.
The data the team used was TrashNet, which was mentioned in the ‘Fine-Tuning Models Comparisons on Garbage Classification for Recyclability’ paper.
Although the accuracy was good, there was a problem, the classification for the class trash (how the trash is categorized) wasn´t. To combat this, the team decided to take their own photos to add more data to the class trash.
Fighting against overfitting
To help the team, Rootstrap conducted a workshop on the basis of neural networks and data science. Throughout the course, we talked in-depth about overfitting. Overfitting is when the model works great with the training data but does not work with real data in use.
During this analysis we applied the following techniques to reduce the overfitting:
Data Augmentation
This technique consists of adding randomness alterations to images to help generate new images. With this, you can augment the original dataset to train the model and make it less specific. The team performed transformations such as rotations, zoom, shift, and shearing the images.
Dropout
This is used when a percentage of the neurons in a hidden layer are randomly deactivated, according to a previously defined probability of discarding. This allows you to test multiple networks in one.
Two dropout layers were added to the pre-trained model, following the criteria of maintaining lower dropout values in the intermediate layers, and a higher value on the end. In principle, it was tested with different pairs (0.5, 0.8 & 0.3, 0.5), with better results than the last option. As a result, we kept these values.
Early Stopping
The model was trained for a maximum of 100 epochs, and the functionality provided by tensorflow.keras.callbacks EarlyStopping was used to determine the best iteration to avoid overfitting. Setting patience=2, indicates that if during 2 epochs there is no progress on the validation set, the training would stop. This progress is seen in the loss function.
Cross-validation
Cross-validation is a statistical method that has a parameter called k that refers to the jumper of groups to split your data into. After dividing the data into ‘k groups’, it is repeated in the following process k times i.e take one group as the test set and another as training, fit the model to the training data, and evaluate the results on the test. This process was followed with 5 folds (k=5).
The following Hyperparameters were used:
- learning rate: 1e-4
- dropout: 0.3 and 0.5
- early stopping patience: 2
- cross-validation folds: 5
The final accuracy was 92%. This is very good accuracy, but, when we started using the app the model did not perform as well as this. This needed solving.
Why did we have this problem?
At this stage of development, Rootstrap's developers took control of the project. They analyzed the problem and detected that the trash being generated did not match consistently with the images the model was trained on. Therefore, they knew the problem was with the data, highlighting once again why data in AI is so important.
So, our new plan was to take photos directly from the trash that we were generating so we could retrain the model. To do this, our Dev Team added an option in the app for users to directly contribute using machine learning.
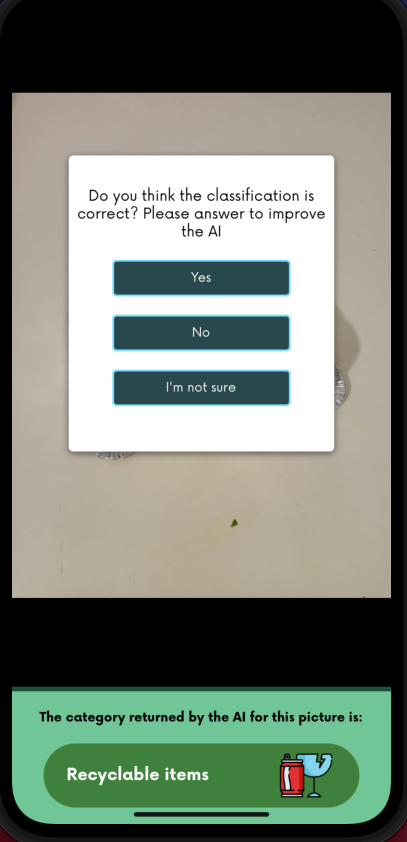
Another issue we discovered was that the current classification was too tied to Abito’s aforementioned classifying rules. This could present future issues, so we decided to not be so specific to Abito’s current rules and classes. So, in the app, our developers set up their own unique conditions.
This way, the model is more generic and might be useful not only for Abito but other companies or cities when classifying. Even if Abito were to change their rules, it would be less costly for us this way to make the corresponding changes to the app.
For example, in the app's info section, you can find information for each class, like below:

The final classes in the model now consisted of:
- Cardboard
- Compost
- Glass
- Metal
- Paper
- Plastic
- Trash
Getting the all important data
After our initial plan failed, we had another problem with our strategy, it was taking too long. This is because we needed to motivate people to take pictures, we had test devices at the Rootstrapoffice but it was sparse as a result of the pandemic, and we had to wait until we had actual trash built up to take pictures.
So, we had to find another way to get images quicker. This is where we got the idea to search for more specific images on the web. We used Bing as our chosen browser as it has an HTTP API, and we developed a script in python to make different requests to the API in both English and Spanish. You can find the repo our Developers used here.
Data assumptions
We made two key assumptions while getting the data to train the model:
- People will generally take close-up photos.
- There were no other objects in the photos.
These assumptions helped us simplify and resolve the problem. We left a plain white surface at the office for Rootstrap's employees to set waste on to take pictures of their trash, before dispensing it in the corresponding basket.
Data cleaning
These images were manually cleaned, and we removed the ones that were not useful or were moved to another folder if they were in the wrong category. The data was divided into two sets: train and test.
You can find the final data we used here. The final dataset contained 2426 for training and 611 for testing.We also used data augmentation, as well as the Resnet pre-trained model like our PIS University team did. You can find the code in this repo.
Our Dev Team decided to use Fastai to train a ResNet network. First off, we used Resnet50 and were curious about what the results with Resnet34 would be, as we noticed that with very few epochs it reached a high performance. When we trained with Resnet34, the results were almost the same, noticing a slight improvement in the trash classification.
More images were added when helping to find specific problems in the dataset when analyzing the classification results. For example:
- Not having any transparent glass images made the model confuse images with plastic.
- Not having enough variety of elements in the plastic category made it think that all bottles were made of plastic.
Finally, with Resnet34 (our final model for the app), we reached an accuracy of 0.98%. Below we see the confusion matrix for this model, a summary of the predicted results in a classification problem. It shows the number of correct and incorrect predictions broken down by each class.

Confusion Matrix
Ongoing model improvement
Every day we are generating more and more data that is being collected by the app. With this, we are able to retrain the model with more realistic data. When using the app to classify an object, users are asked if it was correctly classified.
When the answer is no it's key that users provide this feedback to the app. This allows us to retrain the model with that information, and find patterns in wrong classifications that show why the object was incorrectly classified.
Try out our model
Do you find this model useful and would like to try it by yourself? If so, check out this Google Colab and use the model with your own images. There are examples there to help you.
We also set up the following webpage where users can directly invoke our classifier, upload their image and then check which class is related to it.
If this is an important topic to you and you would like to contribute to the project, feel free to make a pull request at the following repo.
Waste classification examples
Using the Fiftyone tool, we can check the predicted labels against the original labels for each image presented. This set of images refers to the testing data, i.e. images that the model did not see.
We can see that it predicts with high accuracy the classes for each image. In this example, green tags correspond to the real classes, and violet tags represent the predicted classes.

Waste classification examples

Waste classification images
Analyzing incorrect classifications
The below test set has 598 photos in which only 7 have been incorrectly classified. We can see these photos displayed below. But, we need to ask ourselves, are they really incorrectly classified, or were the original images incorrectly tagged?

Incorrect waste classifications
This highlights the complexity of dealing with this problem. As some of the images have been incorrectly classified with this concept, users that tagged the image decided that it was trash or paper. For some people, the dirty paper would be trash, but it is still paper.
To combat this, we must review our decisions when manually splitting images into different folders and re-train the model to resolve those cases. It is not the model that is wrong here, as these decisions were taken by humans when manually classifying the images.
This further highlights why we need this type of model to help us to make the correct choices when choosing which basket to use and disposing of waste correctly in general in our everyday lives.
Would you like to work with similar AI and machine learning technologies? If so, check out our careers page and come join us.


