





In the Rails world most of the apps are just the typical off the shelf monolithic system, and that’s fine; but what happens when we need to move out of that architectural paradigm, towards something like microservices, to meet our business needs?
When our product grows in size so does the complexity of our app. This complexity affects not only our development times, but the quality of our code, sometimes not being able to meet certain needs because the changes needed require to untangle years worth of code. Does this mean we have to use microservices to solve those issues?
Microservices provide several benefits, which differ based on what definition you use. Most definitions include benefits like performance boost, heterogenous tech stacks, independent highly cohesive product/development teams, separation of concerns and domains, and so forth. This makes it a compelling choice when deciding between different architectures to implement.
All of the aforementioned benefits don’t apply only to microservices though, we don’t need to go down that rabbit hole to get them. I would even go as far as saying that microservices are not needed and it’s just a case of over-engineering a solution in most cases. One of the main drawbacks is the added complexity they bring to the table, which might be an unsavory trade-off for what you get in return.
The purpose of this series of articles is to apply several patterns from the microservices world (e.g. Saga, Transactional Outbox, Log Aggregation and Access Token) to a monolithic but modular Rails app, hopefully showing how we can use several proven solutions to create a simpler setup, without moving away from what a good old monolith provides us.
This first installment is focused on distributed data consistency. Following articles will focus on error tracking for multiples services and authentication so stay tuned!
If you are interested in following along with the code, this repo has everything that being discussed in this article. Also this blog is a written continuation of my RailsConf 2023 talk, so if you want more context and a live demo of a solution, be sure to check it out!
The Consequences of Multiple Databases in Monolithic Deployments
Painting the picture
To shed some light into this particular subject and make some sense of the examples coming up, let’s imagine we are working on an app which allows members to schedule meetings. Let’s say we have a Member model to represent our customers and it has a dependency with a UserRegistration model where we have our registration constraints and business rules a user has to meet.
When we register we create a UserRegistration record, after certain validations (e.g. email confirmation) we determine it’s a valid registration so we create a corresponding Member record.
How would we do this in a monolithic app? It could look like the following.
CODE: https://gist.github.com/guillermoap/08e6d1dea5c1f1cb372ad7157463da67.js?file=member.rb
CODE: https://gist.github.com/guillermoap/08e6d1dea5c1f1cb372ad7157463da67.js?file=user_registration.rb
We use a transaction so that if either the confirmation or the member creation fails for whatever reason, the application remains in a consistent data state. This of course is a very simple example, but it serves the purpose of illustrating how something so trivial becomes much more complex when we move away from the common centralized setup.
Now imagine that instead of everything living in the same database and modules having direct dependencies with each other we want to create a level of separation between them. We could achieve this by implementing Domain-Driven Design (DDD). Let’s separate everything regarding registration, roles, permissions into its own domain and have our member business logic in another domain.
We could use the same database for all of our domains, or follow one of the most widely used patterns in microservices architecture and have one database per domain. There are several reasons for this, including being required to comply with GDPR, improving performance, or in our case, strict separation of domains. However, it's important to note that this approach comes with a cost: the management of distributed transactions.
The scenario I’m trying to paint in your mind, although far-fetched for this simple example, is a very common scenario for apps that have moved away from the initial phase and have grown into an established product. So what happens when our app looks like that?
The problem
If we decide to follow that architectural paradigm and make all of those changes then we would have one DB for each domain, meaning we would have a distributed system.
Distributed systems present the problem of distributed data consistency. In distributed systems we don’t have all of the ACID properties we have in a centralized system. The main problem comes down to consistently resolving transactions across multiple databases.
There are patterns that solve this
To solve this issue synchronously we can implement the Two Phase Commit pattern.
Given that this approach is synchronous, it carries with it some disadvantages such as latency and dependencies between participants, meaning that a slow participant affects the whole flow. Here’s a good synthesis on the subject.
To solve this issue asynchronously we can implement the Saga pattern.
This approach consists of having eventual consistency via local transactions in each system. We can have an orchestrated saga or a choreographed one. We are going to discuss the choreographed approach.
In a choreographed saga, each local transaction makes the necessary changes and then emits an event. Other systems are listening for these events to start their own local transactions. If any given transaction fails, we rollback the changes locally (here we do have ACID properties) and then emit an event to rollback changes in other systems, eventually reaching a consistent state.
The pros of following this approach is that we don’t introduce more coupling between systems or domains, we make use of local transactions making that step simpler and also (given its async nature) we don’t need to worry about a slow participant in the flow.
The cons are that it’s a much more complex process. We introduce different infrastructure needs, such as having and managing messaging queues. We also need to be clear on the event flow the different systems are expecting, this is specially important when working with distributed domain-specific teams.
A perfect solution doesn’t exist
Both patterns have their own pros and cons, and it’s up to the engineering team to use the pattern that fits best with their needs.
Given that our goal is to implement this in a modular app, where we value highly cohesive and loosely coupled domains it makes sense to go for the Saga pattern.
Distributed is better, right?
Separating the domains
As previously mentioned we’re going to divide our app into two domains.
We will have a UserAccess domain for everything related to registration, roles, permissions, and a Meetings domain for everything related to our main business logic. UserRegistration will live inside UserAccess and Member will live inside Meetings. Each domain will have its own database.
Now our transaction has to span two separate databases and not only that, but we want our domain to depend on each other as little as possible. So how do we achieve the same transactional behavior we had in our previous example, but with our new domain? It’s time to queue in our Message Bus, pun intended. This could be achieved synchronously with ActiveSupport::Notifications, or asynchronously using ActiveJob with Redis, or using Kafka or RabbitMQ.
As we stated before the saga pattern consists of async distributed local transactions, which communicate via events. Our new message bus is going to be the bridge for the communication between our domains.
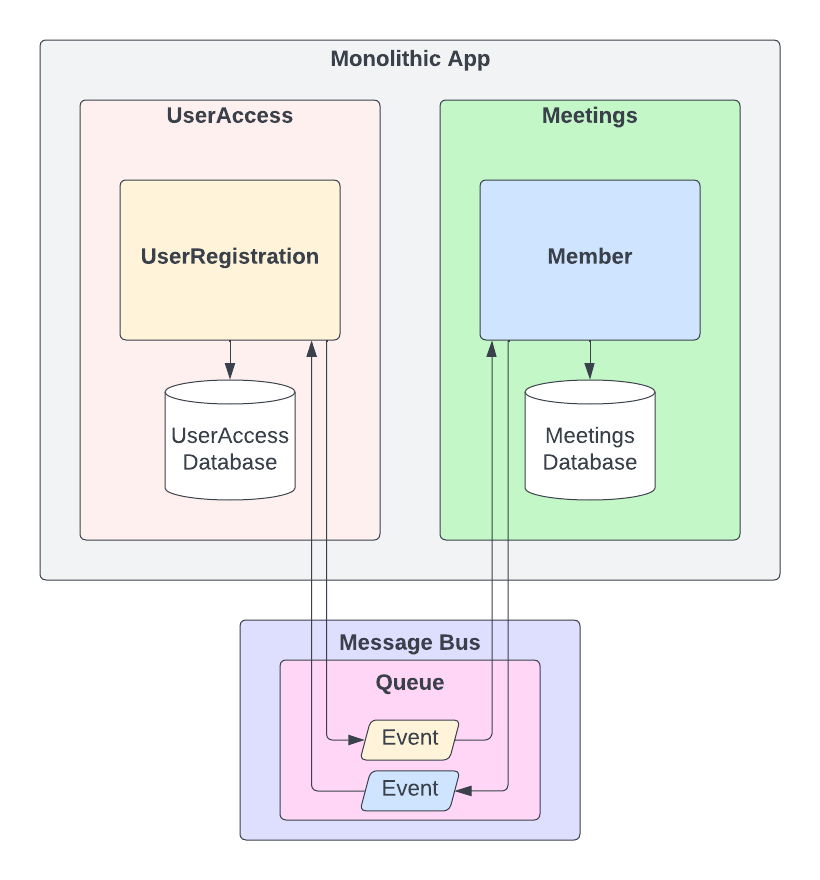
Same dance, different music
Now we are gonna try and recreate what we had in our previous example but with our new domain. Since we can’t communicate directly with the other domain, when making a change that needs to trigger something we will publish an event. We will have a listener for such event that will consume it and execute the appropriate code. Sounds simple enough, right?
What can go wrong
The execution of something and the corresponding event publication must be atomic, if not we run into the problem of having an inconsistent state. To illustrate this let’s take a look at the following example.
CODE: https://gist.github.com/guillermoap/08e6d1dea5c1f1cb372ad7157463da67.js?file=user_access_user_registration.rb
CODE: https://gist.github.com/guillermoap/08e6d1dea5c1f1cb372ad7157463da67.js?file=meetings_member.rb
This is the same code we had to confirm the UserRegistration but now we have separated the Member creation step. What happens if we successfully confirm the UserRegistration record but the publication of the event fails? We end up with a confirmed record but no corresponding Member since the event failed to be published.
In order to avoid this issue and make sure our event publication is atomic we are going to introduce another pattern called Transactional Outbox.
Transactional Outbox
What does this pattern consist of? The core concept is that every event now is persisted as a record. Once we create an Outbox record we then process it and publish the event.
There are two patterns for processing the events in the Outbox table:
Polling Publisher: A worker that polls the table for new records, processing them and publishing the event. Simple and straight forward to implement. Less scalable and tricky to publish events in the correct order.
Transaction Log Tailing: We monitor the database transaction log publishing events when a new record is inserted in the table. More complex since the implementation has to read the transaction log of the database. More scalable since we are reading directly off of the transaction log, ensuring the processing will be in the correct order. Could use a third-party worker like Kafka Connect.
We are going to follow the Transaction Log Tailing pattern but we will not go in depth on how it’s implemented.
The main concept to understand is that we have a way of processing the outbox records so if anything fails, we are certain the event will eventually be published. We know that since it’s persisted in the database, the action that triggered the event ran successfully, because if not, the record would have been rolled back.
Using the outbox
Now that we have established what the Transactional Outbox is, we are going make use of it in our example.
CODE: https://gist.github.com/guillermoap/08e6d1dea5c1f1cb372ad7157463da67.js?file=new_user_access_user_registration.rb
CODE: https://gist.github.com/guillermoap/08e6d1dea5c1f1cb372ad7157463da67.js?file=new_meetings_member.rb
Here we can see that the event publication is now handled by our outbox, creating our record with the event payload we want to send. Once this record is created, it will be picked up by our worker and published to the message queue so that our Meetings domain can consume the event and create the corresponding Member.
As mentioned above, what we gain from doing this is that we persist the state of our flow. We know that if we have a record in the outbox table that means that the associated flow ran successfully, if not the record would’ve been rolled back, and we are assured that we can safely publish that event.
Once published we can proceed to remove the record from the outbox table or just mark it as processed. If the publication fails then we still have the record persisted so we don’t suffer the same problem we had in our Example #2a.
Now that we have all of our building blocks ready we are going to jump back to saga and how we can leverage all of these patterns to achieve our goal of distributed async transactions.
Choreographing our saga
The first thing we are going to do is define the flow for our events. This is very important because it gives us the big picture as to which events need to be triggered and to make sure our rollback process is correct. The rollback should leave us in the same state we had at the start of the flow.
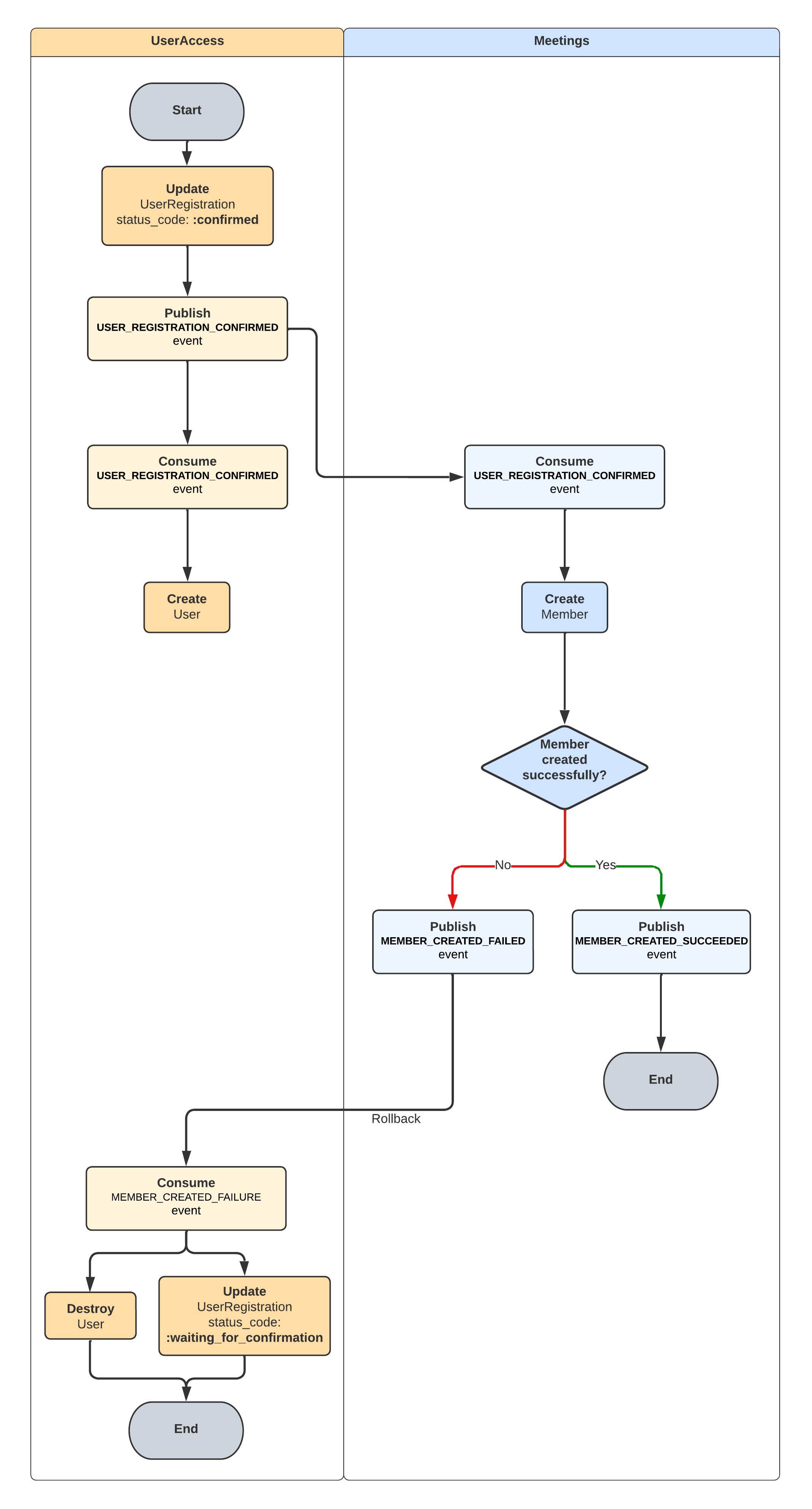
How does this look in the code?
ℹ️ The outbox creation code is going to be explicit so it’s clear what’s happening. If you want to streamline this process check out the https://github.com/rootstrap/active_outbox gem we’ve built specifically for that.
On the UserAccess domain we will have a way to rollback our confirmation, matching how we make the confirmation happen. While in Meetings we will trigger the events depending on the success of the creation of the record. If we fail to create the Member, the MEMBER_CREATED_FAILURE event will be consumed and we will rollback the confirmation for that UserRegistration.
CODE: https://gist.github.com/guillermoap/08e6d1dea5c1f1cb372ad7157463da67.js?file=complete_user_access_user_registration.rb
CODE: https://gist.github.com/guillermoap/08e6d1dea5c1f1cb372ad7157463da67.js?file=complete_meetings_member.rb
This might not look too different from our initial example, but behind the scenes we’re using everything we’ve been talking about and meeting our goals of indirect communication between our decoupled domains.
UserRegistration doesn’t know that there’s a Member associated to it, and vice-versa. The way we keep them linked is by sharing the identifier, but since this is not a foreign key the responsibility of correctly handling that moves away from the database constrains onto the developer.
What was a simple database transaction now becomes an intricate flow, spanning different domains and databases, needing message queues and specific event contracts for it to work.
What to take away
When we face the problem of scaling our product as an organization, the solution is not always microservices. We can leverage what works best for our teams and find solutions that bring in the best of both worlds.
I think moving to an intermediate step of a modular monolith is a good example of finding this compromise, where we get the benefits of creating strict boundaries allowing us to have highly cohesive, independent development teams and workflows. Additionally, concepts such as Saga and Transactional Outbox can be used outside of a microservices architecture to maintain data consistency and reliability without skyrocketing the infrastructure complexity and costs that come with such an architectural design.
Our biggest challenge is to find the balance where our solution doesn’t devolve into a more complex app than the one we had in the first place, both in the actual system and the development process. Hopefully, this article succeeded in showing an example of how this balance can be achieved through the use of a modular monolith and data consistency techniques like Saga and Transactional Outbox.
Stay tuned for the next installments where we continue our modular journey!


